
21
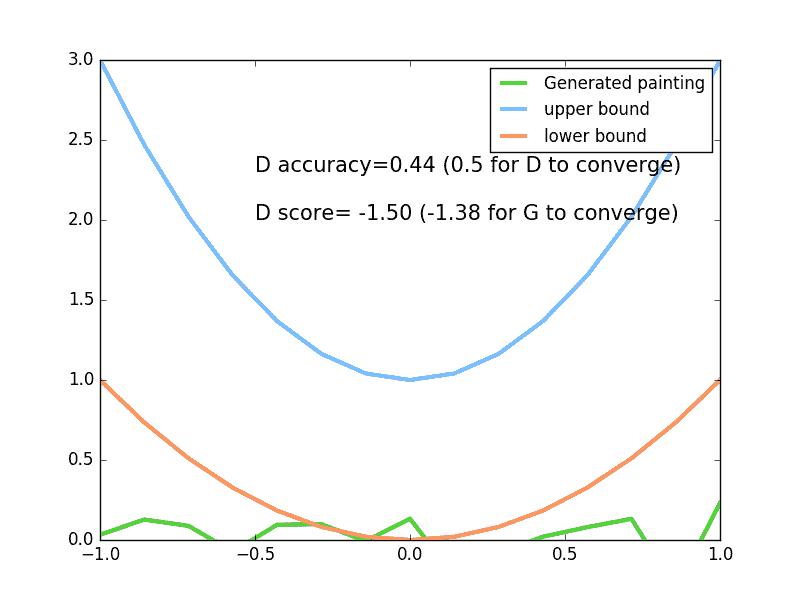
4.6 – GAN (Generative Adversarial Nets 生成对抗网络)GAN 是一个近几年比较流行的生成网络形式. 对比起传统的生成模型, 他减少了模型限制和生成器限制, 他具有有更好的生成能力. 人们常用假钞鉴定者和假钞制造者来打比喻, 但是我不喜欢这个比喻, 觉得没有真实反映出 GAN 里面的机理. 所以我的一句话介绍 GAN 就是: Generator 是新手画家, Discriminator 是新手鉴赏家, 你是高级鉴赏家. 你将著名画家的品和新手画家的作品都给新手鉴赏家评定, 并告诉新手鉴赏家哪些是新手画家画的, 哪些是著名画家画的, 新手鉴赏家就慢慢学习怎么区分新手画家和著名画家的画, 但是新手画家和新手鉴赏家是好朋友, 新手鉴赏家会告诉新手画家要怎么样画得更像著名画家, 新手画家就能将自己的突然来的灵感 (random noise) 画得更像著名画家. 我用一个短动画形式来诠释了整个过程 (GAN 动画简介) (如下). 下面是本节内容的效果, 绿线的变化是新手画家慢慢学习如何踏上画家之路的过程. 而能被认定为著名的画作在 upper boun...

22
高阶内容
23
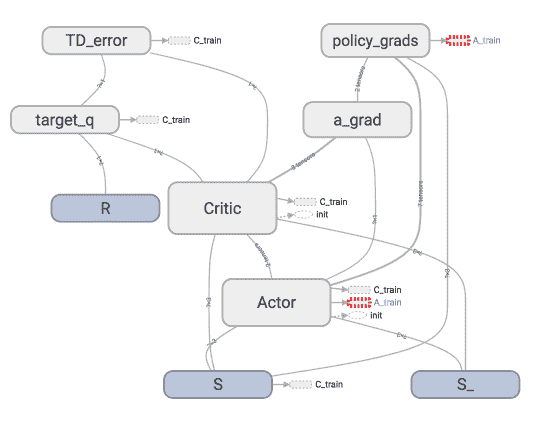
5.1 – 为什么 Torch 是动态的听说过 Torch 的人都听说了 torch 是动态的, 那他的动态到底是什么呢? 我们用一个 RNN 的例子来展示一下动态计算到底长什么样. 动态?静态?对比静态动态, 我们就得知道谁是静态的. 在流行的神经网络模块中, Tensorflow 就是最典型的静态计算模块. 下图是一种我在强化学习教程中的 Tensorflow 计算图. 也就是说, 大部分时候, 用 Tensorflow 是先搭建好这样一个计算系统, 一旦搭建好了, 就不能改动了 (也有例外, 比如 dynamic_rnn() , 但是总体来说他还是运用了一个静态思维), 所有的计算都会在这种图中流动, 当然很多情况, 这样就够了, 我们不需要改动什么结构. 不动结构当然可以提高效率. 但是一旦计算流程不是静态的, 计算图要变动. 最典型的例子就是 RNN, 有时候 RNN 的 time step 不会一样, 或者在 training 和 testing 的时候, batch_size 和 time_step 也不一样, 这时, Tensorflow 就头疼了, Tens...
25
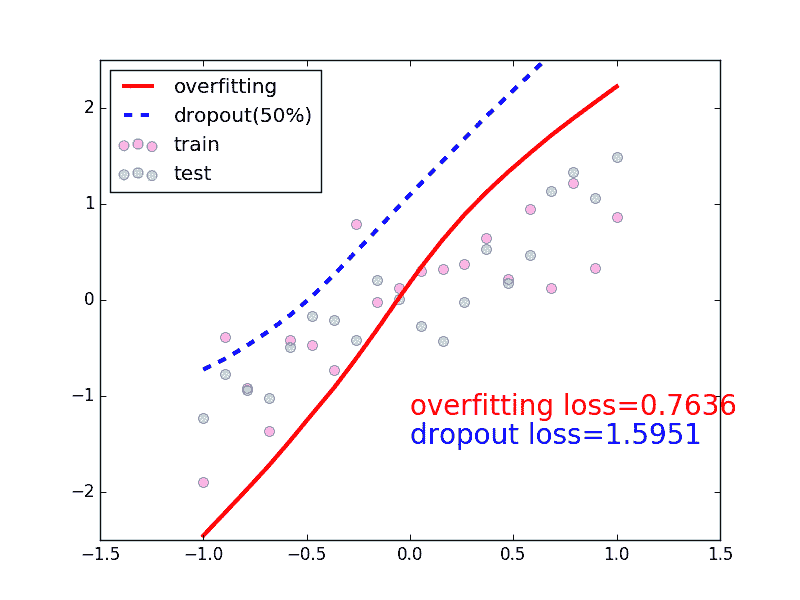
5.3 – Dropout 防止过拟合过拟合让人头疼, 明明训练时误差已经降得足够低, 可是测试的时候误差突然飙升. 这很有可能就是出现了过拟合现象. 强烈推荐通过(下面)这个动画的形式短时间了解什么是过拟合, 怎么解决过拟合. 下面动图就显示了我们成功缓解了过拟合现象. 做点数据自己做一些伪数据, 用来模拟真实情况. 数据少, 才能凸显过拟合问题, 所以我们就做10个数据点. 12345678910111213141516171819202122232425import torchfrom torch.autograd import Variableimport matplotlib.pyplot as plttorch.manual_seed(1) # reproducibleN_SAMPLES = 20N_HIDDEN = 300# training datax = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)y = x 0.3*torch.normal(torch.zeros(N_SAMPLES, ...

24
5.2 – GPU 加速运算在 GPU 训练可以大幅提升运算速度. 而且 Torch 也有一套很好的 GPU 运算体系. 但是要强调的是: 你的电脑里有合适的 GPU 显卡(NVIDIA), 且支持 CUDA 模块. 请在NVIDIA官网查询 必须安装 GPU 版的 Torch, 点击这里查看如何安装 用 GPU 训练 CNN这份 GPU 的代码是依据之前这份CNN的代码修改的. 大概修改的地方包括将数据的形式变成 GPU 能读的形式, 然后将 CNN 也变成 GPU 能读的形式. 做法就是在后面加上 .cuda() , 很简单. 1234567...test_data = torchvision.datasets.MNIST(root=\'./mnist/\', train=False)# !!!!!!!! 修改 test data 形式 !!!!!!!!! #test_x = Variable(torch.unsqueeze(test_data.test_data, dim=1)).type(torch.FloatTensor)[:2000].cuda...
26
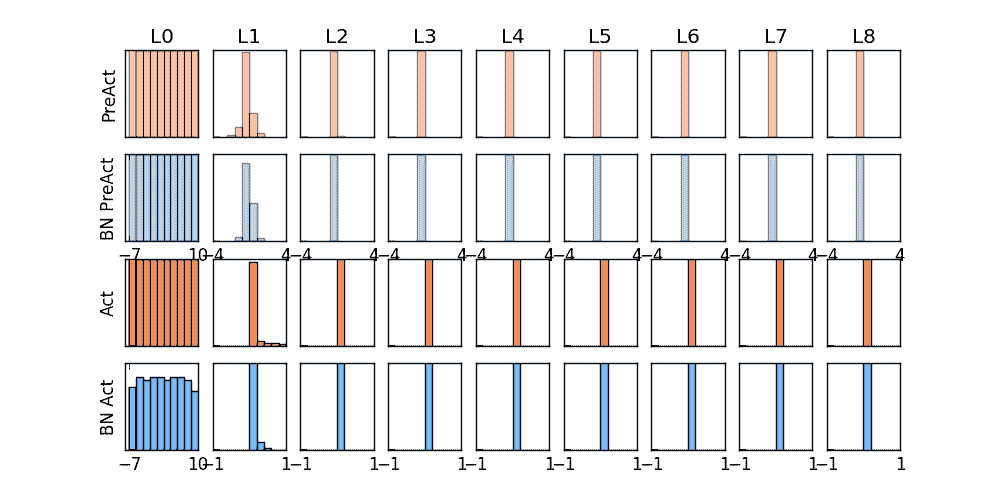
5.4 – Batch Normalization 批标准化批标准化通俗来说就是对每一层神经网络进行标准化 (normalize) 处理, 我们知道对输入数据进行标准化能让机器学习有效率地学习. 如果把每一层后看成这种接受输入数据的模式, 那我们何不 “批标准化” 所有的层呢? 具体而且清楚的解释请看到 我(原作者)制作的 什么批标准化 动画简介(推荐)(如下). 那我们就看看下面的两个动图, 这就是在每层神经网络有无 batch normalization 的区别啦. 做点数据自己做一些伪数据, 用来模拟真实情况. 而且 Batch Normalization (之后都简称BN) 还能有效的控制坏的参数初始化 (initialization), 比如说 ReLU 这种激励函数最怕所有的值都落在附属区间, 那我们就将所有的参数都水平移动一个 -0.2 ( bias_initialization = -0.2 , 来看看 BN 的实力. 12345678910111213141516171819202122232425262728293031323334353...
1 模型预处理
# 第一章 模型预处理 > 作者:Trent Hauck > 译者:[muxuezi](https://muxuezi.github.io/posts/1-premodel-workflow.html) > 协议:[CC BY-NC-SA 4.0](http://creativecommons.org/licenses/by-nc-sa/4.0/) 本章包括以下主题: 1. [从外部源获取样本数据](getting-sample-data-from-external-sources.html) 1. [创建试验样本数据](creating-sample-data-for-toy-analysis.html) 1. [把数据调整为标准正态分布](scaling-data-to-the-standard-normal.html) 1. [用阈值创建二元特征](creating-binary-features-through-thresholding.html) 1. [分类变量处理](working-with-categorical-variables.html) 1....
2 处理线性模型
第二章 处理线性模型 作者:Trent Hauck 译者:muxuezi 协议:CC BY-NC-SA 4.0 本章包括以下主题: 线性回归模型 评估线性回归模型 用岭回归弥补线性回归的不足 优化岭回归参数 LASSO正则化 LARS正则化 用线性方法处理分类问题——逻辑回归 贝叶斯岭回归 用梯度提升回归从误差中学习 简介线性模型是统计学和机器学习的基础。很多方法都利用变量的线性组合描述数据之间的关系。通常都要花费很大精力做各种变换,目的就是为了让数据可以描述成一种线性组合形式。 本章,我们将从最简单的数据直线拟合模型到分类模型,最后介绍贝叶斯岭回归。 2.1 线性回归模型现在,我们来做一些建模!我们从最简单的线性回归(Linear regression)开始。线性回归是最早的也是最基本的模型——把数据拟合成一条直线。 Getting readyboston数据集很适合用来演示线性回归。boston数据集包含了波士顿地区的房屋价格中位数。还有一些可能会影响房价的因素,比如犯罪率(crime rate)。 首先,让我们加载数据: 12from sklearn ...
3 使用距离向量构建模型
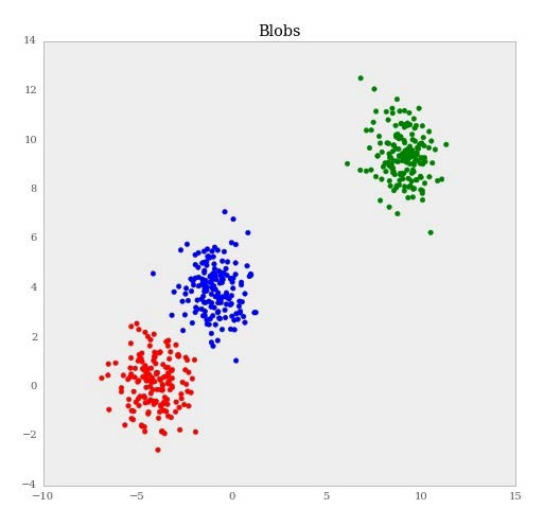
第三章 使用距离向量构建模型 作者:Trent Hauck 译者:飞龙 协议:CC BY-NC-SA 4.0 这一章中,我们会涉及到聚类。聚类通常和非监督技巧组合到一起。这些技巧假设我们不知道结果变量。这会使结果模糊,以及实践客观。但是,聚类十分有用。我们会看到,我们可以使用聚类,将我们的估计在监督设置中“本地化”。这可能就是聚类非常高效的原因。它可以处理很大范围的情况,通常,结果也不怎么正常。 这一章中我们会浏览大量应用,从图像处理到回归以及离群点检测。通过这些应用,我们会看到聚类通常可以通过概率或者优化结构来观察。不同的解释会导致不同的权衡。我们会看到,如何训练模型,以便让工具尝试不同模型,在面对聚类问题的时候。 3.1 使用 KMeans 对数据聚类聚类是个非常实用的技巧。通常,我们在采取行动时需要分治。考虑公司的潜在客户列表。公司可能需要将客户按类型分组,之后为这些分组划分职责。聚类可以使这个过程变得容易。 KMeans 可能是最知名的聚类算法之一,并且也是最知名的无监督学习技巧之一。 准备首先,让我们看一个非常简单的聚类,之后我们再讨论 KMeans 如何工作...
5 模型后处理
第五章 模型后处理 作者:Trent Hauck 译者:飞龙 协议:CC BY-NC-SA 4.0 5.1 K-fold 交叉验证这个秘籍中,我们会创建交叉验证,它可能是最重要的模型后处理验证练习。我们会在这个秘籍中讨论 k-fold 交叉验证。有几种交叉验证的种类,每个都有不同的随机化模式。K-fold 可能是一种最熟知的随机化模式。 准备我们会创建一些数据集,之后在不同的在不同的折叠上面训练分类器。值得注意的是,如果你可以保留一部分数据,那是最好的。例如,我们拥有N = 1000的数据集,如果我们保留 200 个数据点,之后使用其他 800 个数据点之间的交叉验证,来判断最佳参数。 工作原理首先,我们会创建一些伪造数据,之后测试参数,最后,我们会看看结果数据集的大小。 1234>>> N = 1000 >>> holdout = 200>>> from sklearn.datasets import make_regression >>> X, y = make_regression(1000...




