

SUMMARY
Scikit-learn 秘籍 第一章 模型预处理 第二章 处理线性模型 第三章 使用距离向量构建模型 第四章 使用 scikit-learn 对数据分类 第五章 模型后处理
4 使用 scikit-learn 对数据分类
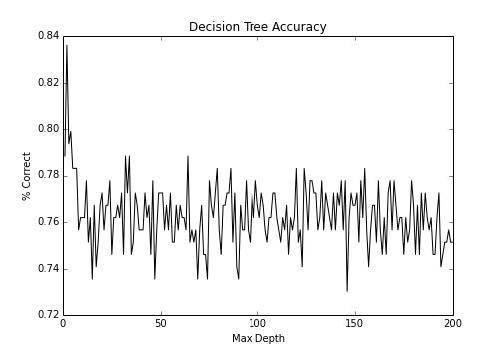
第四章 使用 scikit-learn 对数据分类 作者:Trent Hauck 译者:飞龙 协议:CC BY-NC-SA 4.0 分类在大量语境下都非常重要。例如,如果我们打算自动化一些决策过程,我们可以利用分类。在我们需要研究诈骗的情况下,有大量的事务,人去检查它们是不实际的。所以,我们可以使用分类都自动化这种决策。 4.1 使用决策树实现基本的分类这个秘籍中,我们使用决策树执行基本的分类。它们是非常不错的模型,因为它们很易于理解,并且一旦训练完成,评估就很容易。通常可以使用 SQL 语句,这意味着结果可以由许多人使用。 准备这个秘籍中,我们会看一看决策树。我喜欢将决策树看做基类,大量的模型从中派生。它是个非常简单的想法,但是适用于大量的情况。 首先,让我们获取一些分类数据,我们可以使用它来练习: 123>>> from sklearn import datasets >>> X, y = datasets.make_classification(n_samples=1000, n_features=3, ...

SUMMARY
其他示例 双聚类 频谱共聚算法演示 频谱双聚类算法演示 使用频谱共聚算法对文档进行聚合 校准 分类 多聚类 协方差估计 交叉分解 数据集示例 决策树 分解 集成方法 基于真实数据集的示例 特征选择 高斯混合模型 高斯机器学习过程 广义线性模型 Lasso 和弹性网络在稀疏信号上的表现 Lasso 和弹性网络 Lasso 模型选择:交叉验证 / AIC / BIC 多任务 Lasso 实现联合特征选择 线性回归示例 岭系数对回归系数的影响 压缩感知:用L1先验概率进行断层重建 检查 流行学习 缺失值插补 选型 多输出方法 最近邻 神经网络 管道和复合估计器 预处理 发布要点 半监督分类 支持向量机 建成练习 文本文档工作 分类特征稀疏的文本

1
1. 监督学习 1.1. 广义线性模型 1.1.1. 普通最小二乘法 1.1.2. 岭回归 1.1.3. Lasso 1.1.4. 多任务 Lasso 1.1.5. 弹性网络 1.1.6. 多任务弹性网络 1.1.7. 最小角回归 1.1.8. LARS Lasso 1.1.9. 正交匹配追踪法(OMP) 1.1.10. 贝叶斯回归 1.1.11. logistic 回归 1.1.12. 随机梯度下降, SGD 1.1.13. Perceptron(感知器) 1.1.14. Passive Aggressive Algorithms(被动攻击算法) 1.1.15. 稳健回归(Robustness regression): 处理离群点(outliers)和模型错误 1.1.16. 多项式回归:用基函数展开线性模型 1.2. 线性和二次判别分析 1.2.1. 使用线性判别分析来降维 1.2.2. LDA 和 QDA 分类器的数学公式 1.2.3. LDA 的降维数学公式 1.2.4. Shrinkage(收缩) 1.2.5. 预估算法 1.3. 内核岭回归 1.4. 支持向量...
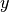
10
1.9. 朴素贝叶斯校验者: @Kyrie @Loopy @qinhanmin2014翻译者: @TWITCH 朴素贝叶斯方法是基于贝叶斯定理的一组有监督学习算法,即“简单”地假设每对特征之间相互独立。 给定一个类别 和一个从 到 的相关的特征向量, 贝叶斯定理阐述了以下关系: 使用简单(naive)的假设-每对特征之间都相互独立: 对于所有的 :i 都成立,这个关系式可以简化为 由于在给定的输入中 是一个常量,我们使用下面的分类规则: 我们可以使用最大后验概率(Maximum A Posteriori, MAP) 来估计 和 ; 前者是训练集中类别 的相对频率。 各种各样的的朴素贝叶斯分类器的差异大部分来自于处理 分布时的所做的假设不同。 尽管其假设过于简单,在很多实际情况下,朴素贝叶斯工作得很好,特别是文档分类和垃圾邮件过滤。这些工作都要求 一个小的训练集来估计必需参数。(至于为什么朴素贝叶斯表现得好的理论原因和它适用于哪些类型的数据,请参见下面的参考。) 相比于其他更复杂的方法,朴素贝叶斯学习器...
11
1.10. 决策树校验者: @文谊 @皮卡乒的皮卡乓 @Loopy翻译者: @I Remember Decision Trees (DTs) 是一种用来 classification 和 regression 的无参监督学习方法。其目的是创建一种模型从数据特征中学习简单的决策规则来预测一个目标变量的值。 例如,在下面的图片中,决策树通过if-then-else的决策规则来学习数据从而估测数一个正弦图像。决策树越深入,决策规则就越复杂并且对数据的拟合越好。 决策树的优势: 便于理解和解释。树的结构可以可视化出来。 训练需要的数据少。其他机器学习模型通常需要数据规范化,比如构建虚拟变量和移除缺失值,不过请注意,这种模型不支持缺失值。 由于训练决策树的数据点的数量导致了决策树的使用开销呈指数分布(训练树模型的时间复杂度是参与训练数据点的对数值)。 能够处理数值型数据和分类数据。其他的技术通常只能用来专门分析某一种变量类型的数据集。详情请参阅算法。 能够处理多路输出的问题。 使用白盒模型。如果某种给定的情况在该模型中是...
12
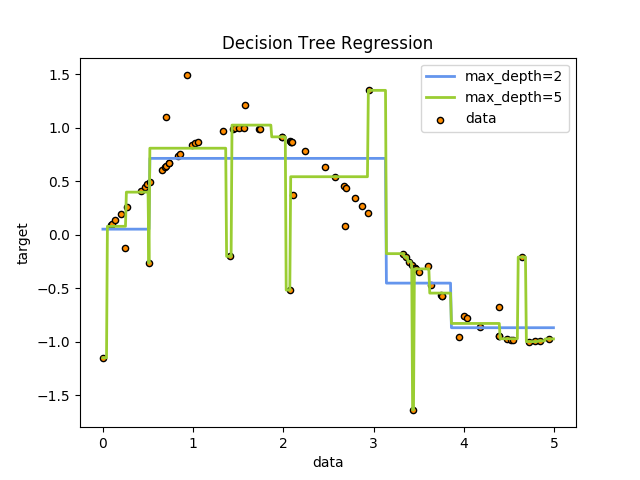
1.11. 集成方法校验者: @Dream on dreamer. @zehuichen123 @JanzenLiu @小瑶 @\S^R^Y/ @Loopy @qinhanmin2014翻译者: @StupidStalker @文谊 @t9UhoI 注意:在本文中 bagging 和 boosting 为了更好的保留原文意图,不进行翻译estimator:估计器 base estimator:基估计器 集成方法 的目标是把多个使用给定学习算法构建的基估计器的预测结果结合起来,从而获得比单个估计器更好的泛化能力/鲁棒性。 集成方法通常分为两种: 平均方法,该方法的原理是构建多个独立的估计器,然后取它们的预测结果的平均。一般来说组合之后的估计器是会比单个估计器要好的,因为它的方差减小了。 示例: Bagging 方法 , 随机森林 , … 相比之下,在 boosting 方法 中,基估计器是依次构建的,并且每一个基估...
13
1.12. 多类和多标签算法校验者: @溪流-十四号 @大魔王飞仙 @Loopy翻译者: @v 警告 scikit-learn中的所有分类器都可以开箱即用进行多类分类。除非您想尝试不同的多类策略,否则无需使用sklearn.multiclass模块。 sklearn.multiclass 模块采用了 元评估器 ,通过把多类 和 多标签 分类问题分解为 二元分类问题去解决。这同样适用于多目标回归问题。 Multiclass classification 多类分类 意味着一个分类任务需要对多于两个类的数据进行分类。比如,对一系列的橘子,苹果或者梨的图片进行分类。多类分类假设每一个样本有且仅有一个标签:一个水果可以被归类为苹果,也可以 是梨,但不能同时被归类为两类。 Multilabel classification 多标签分类 给每一个样本分配一系列标签。这可以被认为是预测不相互排斥的数据点的属性,例如与文档类型相关的主题。一个文本可以归类为任意类别,例如可以同时为政治、金融、 教育相关或者不属于以上任何类别。 Mul...
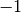
15
1.14. 半监督学习校验者: @STAN,废柴0.1 @Loopy @N!no翻译者: @那伊抹微笑 半监督学习 是指训练数据中一些样本数据没有标签的情况。sklearn.semi_supervised 中的半监督估计器,能够利用这些附加的未标记数据来更好地捕获底层数据分布的形状,并将其更好地类推广到新的样本。当训练数据中有非常少量的有标签的点和大量的无标签的点时,这些算法可以表现良好。 y 中含有未标记的数据 在使用 fit 方法训练数据时,将标识符分配给无标签和有标签的点是尤其重要的。此实现使用的标识符是整数值 。 1.14.1. 标签传播标签传播表示半监督图推理算法的几个变体。 该模型的一些特性如下: 可用于分类和回归任务 使用内核方法将数据投影到备用维度空间 scikit-learn 提供了两种标签传播模型: LabelPropagation 和 LabelSpreading 。 两者都通过在输入数据集中的所有项目上构建相似图来进行工作。 标签传播说明: 无标签的观察值结构与类结构一致,因此可以将类标签传...
14
1.13. 特征选择校验者: @yuezhao9210 @BWM-蜜蜂 @Loopy翻译者: @v 在 sklearn.feature_selection 模块中的类可以用来对样本集进行 feature selection(特征选择)和 dimensionality reduction(降维),这将会提高估计器的准确度或者增强它们在高维数据集上的性能。 1.13.1. 移除低方差特征VarianceThreshold 是特征选择的一个简单基本方法,它会移除所有那些方差不满足一些阈值的特征。默认情况下,它将会移除所有的零方差特征,即那些在所有的样本上的取值均不变的特征。 例如,假设我们有一个特征是布尔值的数据集,我们想要移除那些在整个数据集中特征值为0或者为1的比例超过80%的特征。布尔特征是伯努利( Bernoulli )随机变量,变量的方差为 因此,我们可以使用阈值 ``.8 * (1 - .8)``进行选择: 1234567891011>>> from sklearn....




