
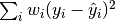
16
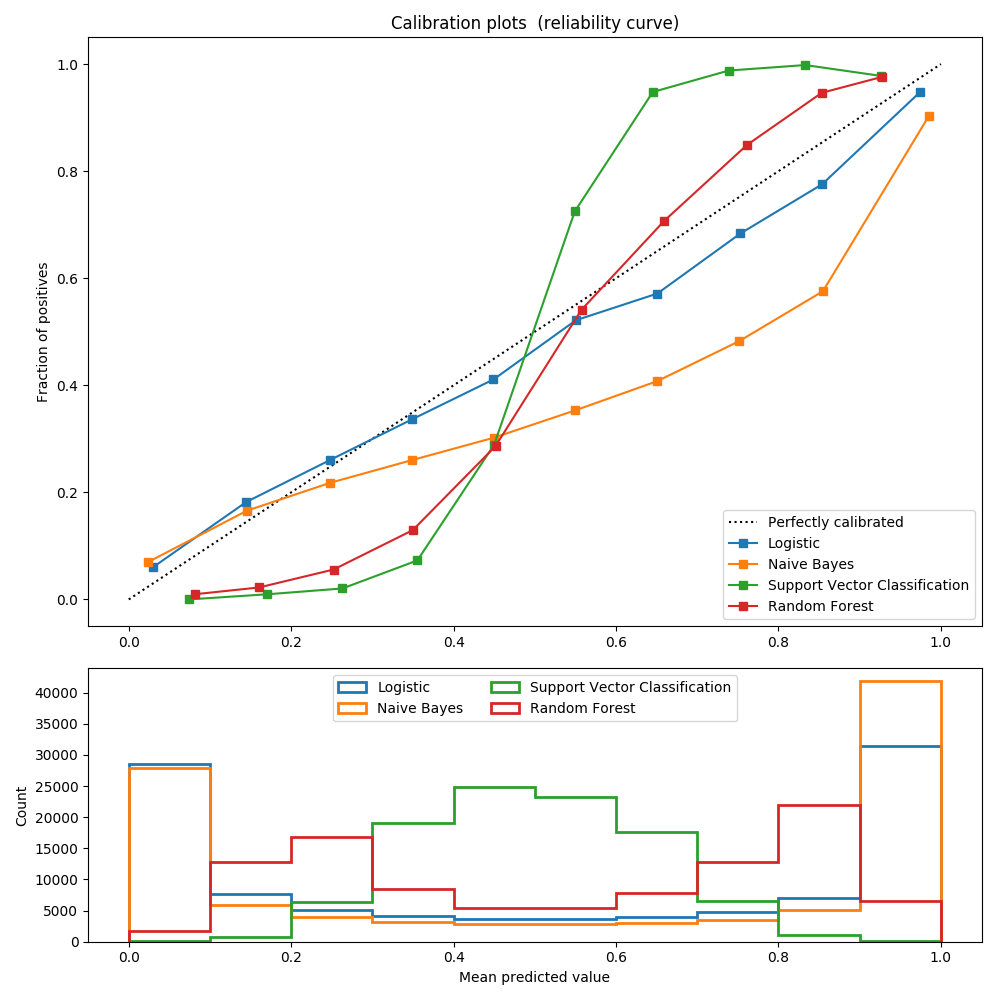
1.15. 等式回归校验者: @STAN,废柴0.1翻译者: @Damon IsotonicRegression 类对数据进行非降函数拟合. 它解决了如下的问题: 最小化 服从于 其中每一个 是 strictly 正数而且每个 是任意实 数. 它生成一个由平方误差接近的不减元素组成的向量.实际上这一些元素形成 一个分段线性的函数.

0SUMMARY
安装 scikit-learn 用户指南 1. 监督学习 1.1. 广义线性模型 1.2. 线性和二次判别分析 1.3. 内核岭回归 1.4. 支持向量机 1.5. 随机梯度下降 1.6. 最近邻 1.7. 高斯过程 1.8. 交叉分解 1.9. 朴素贝叶斯 1.10. 决策树 1.11. 集成方法 1.12. 多类和多标签算法 1.13. 特征选择 1.14. 半监督学习 1.15. 等式回归 1.16. 概率校准 1.17. 神经网络模型(有监督) 2. 无监督学习 2.1. 高斯混合模型 2.2. 流形学习 2.3. 聚类 2.4. 双聚类 2.5. 特征分解降维(矩阵分解问题) 2.6. 协方差估计 2.7. 新奇和异常值检测 2.8. 密度估计 2.9. 神经网络模型(无监督) 3. 模型选择和评估 3.1. 交叉验证:评估估算器的表现 3.2. 调整估计器的超参数 3.3. 模型评估: 量化预测的质量 3.4. 模型持久化 3.5. 验证曲线: 绘制分数以评估模型 4. 检验 4.1. 部分依赖图 5. 数据集转换 5.1. Pipeline(管道...
17
1.16. 概率校准校验者: @曲晓峰 @小瑶翻译者: @那伊抹微笑 执行分类时, 您经常希望不仅可以预测类标签, 还要获得相应标签的概率. 这个概率给你一些预测的信心. 一些模型可以给你贫乏的概率估计, 有些甚至不支持概率预测. 校准模块可以让您更好地校准给定模型的概率, 或添加对概率预测的支持. 精确校准的分类器是概率分类器, 其可以将 predict_proba 方法的输出直接解释为 confidence level(置信度级别). 例如,一个经过良好校准的(二元的)分类器应该对样本进行分类, 使得在给出一个接近 0.8 的 prediction_proba 值的样本中, 大约 80% 实际上属于正类. 以下图表比较了校准不同分类器的概率预测的良好程度: LogisticRegression 默认情况下返回良好的校准预测, 因为它直接优化了 log-loss(对数损失)情况. 相反,其他方法返回 biased probabilities(偏倚概率); 每种方法有不同的偏差: GaussianNB 往往将概率推到 0 或 1(注意...
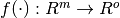
18
1.17. 神经网络模型(有监督)校验者: @tiantian1412 @火星 @Loopy @N!no翻译者: @A 警告 此实现不适用于大规模数据应用。 特别是 scikit-learn 不支持 GPU。如果想要提高运行速度并使用基于 GPU 的实现以及为构建深度学习架构提供更多灵活性的框架,请参阅 Related Projects 。 1.17.1. 多层感知器多层感知器(MLP) 是一种监督学习算法,通过在数据集上训练来学习函数 ,其中 是输入的维数, 是输出的维数。 给定一组特征 和标签 ,它可以学习用于分类或回归的非线性函数。 与逻辑回归不同的是,在输入层和输出层之间,可以有一个或多个非线性层,称为隐藏层。 图1 展示了一个具有标量输出的单隐藏层 MLP。 图1:单隐藏层MLP. 最左层的输入层由一组代表输入特征的神经元 组成。 每个隐藏层中的神经元将前一层的值进行加权线性求和转换 ,再通过非线性激活函数 - 比如双曲正切函数 tanh 。 输出层接收到的值是最后一个隐藏层的输出经...
21
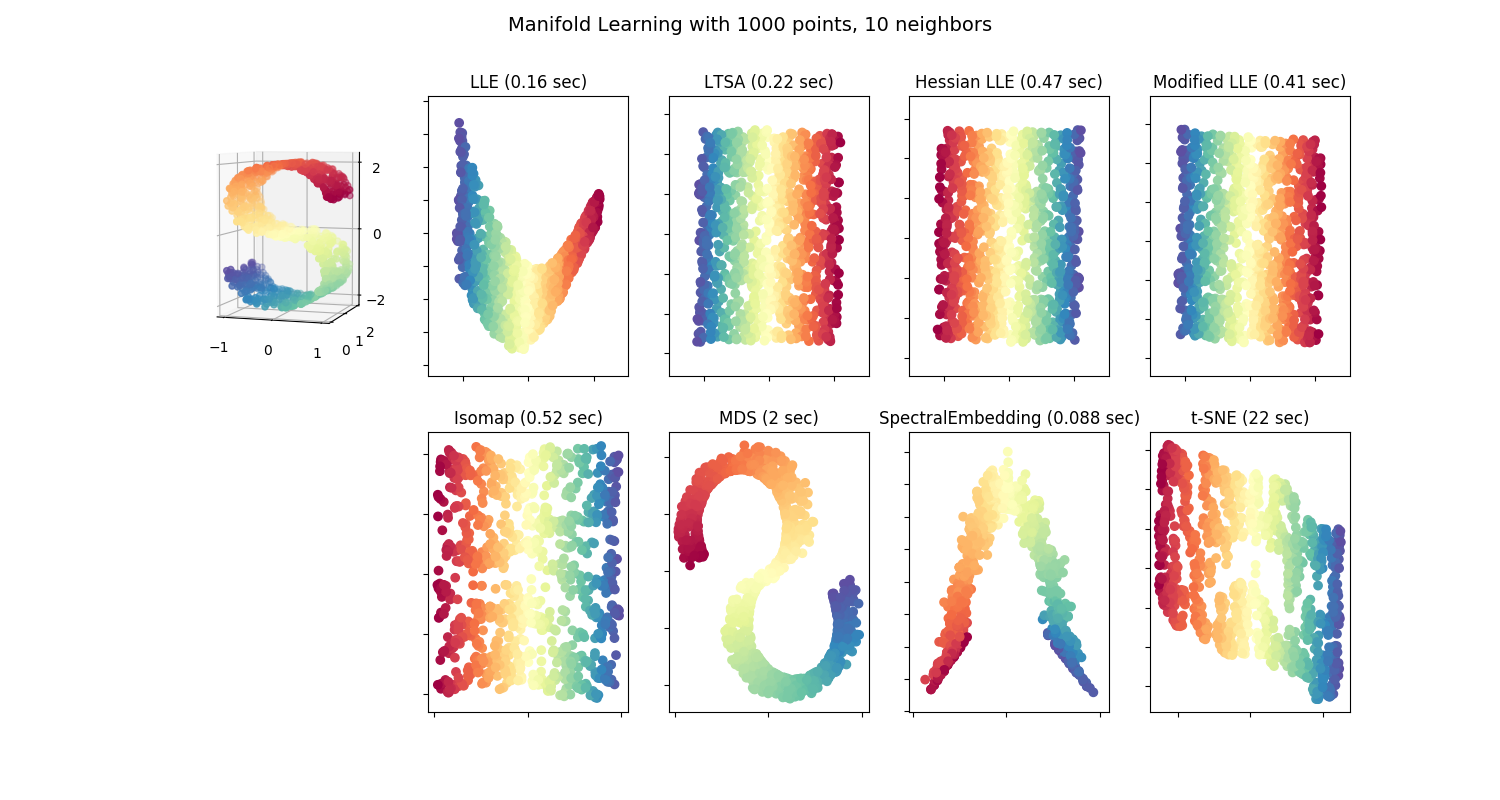
2.2. 流形学习校验者: @XuJianzhi @RyanZhiNie @羊三 @Loopy @barrycg翻译者: @XuJianzhi @羊三 Look for the bare necessities The simple bare necessities Forget about your worries and your strife I mean the bare necessitiesOld Mother Nature’s recipes That bring the bare necessities of life – Baloo的歌 [奇幻森林] 流形学习是一种非线性降维方法。其算法基于的思想是:许多数据集维度过高的现象完全是人为导致得。 2.2.1. 介绍高维数据集通常难以可视化。虽然,可以通过绘制两维或三维的数据来...
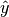
2
# 1.1. 广义线性模型 校验者: [@专业吹牛逼的小明](https://github.com/apachecn/scikit-learn-doc-zh) [@Gladiator](https://github.com/apachecn/scikit-learn-doc-zh) [@Loopy](https://github.com/loopyme) [@qinhanmin2014](https://github.com/qinhanmin2014) 翻译者: [@瓜牛](https://github.com/apachecn/scikit-learn-doc-zh) [@年纪大了反应慢了](https://github.com/apachecn/scikit-learn-doc-zh) [@Hazekiah](https://github.com/apachecn/scikit-learn-doc-zh) [@BWM-蜜蜂](https://g...

19
2. 无监督学习 2.1. 高斯混合模型 2.1.1. 高斯混合 2.1.2. 变分贝叶斯高斯混合 2.2. 流形学习 2.2.1. 介绍 2.2.2. Isomap 2.2.3. 局部线性嵌入 2.2.4. 改进型局部线性嵌入(MLLE) 2.2.5. 黑塞特征映射(HE) 2.2.6. 谱嵌入 2.2.7. 局部切空间对齐(LTSA) 2.2.8. 多维尺度分析(MDS) 2.2.9. t 分布随机邻域嵌入(t-SNE) 2.2.10. 实用技巧 2.3. 聚类 2.3.1. 聚类方法概述 2.3.2. K-means 2.3.3. Affinity Propagation 2.3.4. Mean Shift 2.3.5. Spectral clustering 2.3.6. 层次聚类 2.3.7. DBSCAN 2.3.8. OPTICS 2.3.9. Birch 2.3.10. 聚类性能度量 2.4. 双聚类 2.4.1. Spectral Co-Clustering 2.4.2. Spectral Biclustering 2.4.3. Biclusteri...
20
2.1. 高斯混合模型校验者: @why2lyj @Shao Y. @Loopy @barrycg翻译者: @glassy sklearn.mixture 是一个应用高斯混合模型进行非监督学习的包(支持 diagonal,spherical,tied,full 四种协方差矩阵), (注:diagonal 指每个分量有各自独立的对角协方差矩阵, spherical 指每个分量有各自独立的方差(再注:spherical是一种特殊的 diagonal, 对角的元素相等), tied 指所有分量共享一个标准协方差矩阵, full 指每个分量有各自独立的标准协方差矩阵),它可以对数据进行抽样,并且根据数据来估计模型。同时该包也支持由用户来决定模型内混合的分量数量。 (译注:在高斯混合模型中,我们将每一个高斯分布称为一个分量,即 component) 二分量高斯混合模型: 数据点,以及模型的等概率线。 高斯混合模型是一个假设所有的数据点都是生成于有限个带有未知参数的高斯分布所混合的概率模型。 我们可以将这种混合模型看作...
23
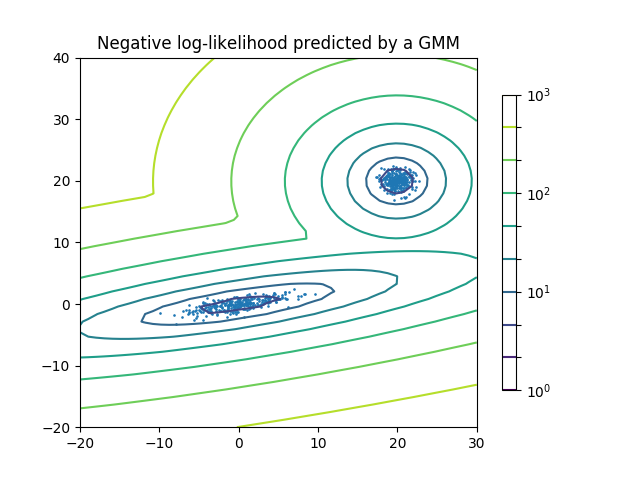
2.4. 双聚类校验者: @udy @barrycg翻译者: @程威 Biclustering(双向聚类) 的实现模块是 sklearn.cluster.bicluster。 双向聚类算法对数据矩阵的行列同时进行聚类。而这些行列的聚类称之为 双向簇(biclusters)。每一次聚类都会基于原始数据矩阵确定一个子矩阵, 并且这些子矩阵具有一些需要的属性。 例如, 给定一个矩阵 (10, 10) , 如果对其中三行二列进行双向聚类,就可以获得一个子矩阵 (3, 2)。 123456789>>> import numpy as np>>> data = np.arange(100).reshape(10, 10)>>> rows = np.array([0, 2, 3])[:, np.newaxis]>>> columns = np.array([1, 2])>>> data[rows, columns]array([[ 1, 2], [21, 22]...
22
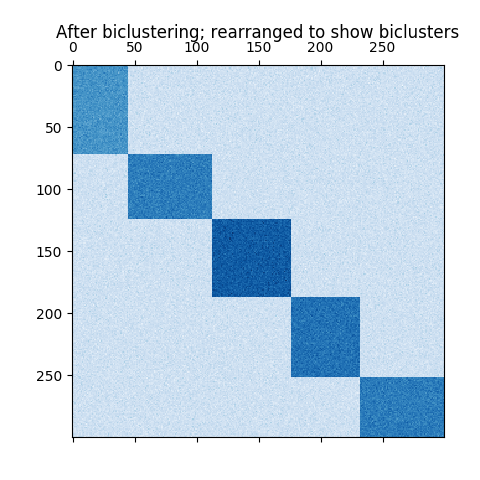
2.3. 聚类校验者: @花开无声 @小瑶 @Loopy @barrycg翻译者: @小瑶 @krokyin 未标记的数据的 聚类(Clustering) 可以使用模块 sklearn.cluster 来实现。 每个聚类算法(clustering algorithm)都有两个变体: 一个是 类(class), 它实现了 fit 方法来学习训练数据的簇(cluster),还有一个 函数(function),当给定训练数据,返回与不同簇对应的整数标签数组(array)。对于类来说,训练数据上的标签可以在 labels_ 属性中找到。 输入数据 需要注意的一点是,该模块中实现的算法可以采用不同种类的矩阵作为输入。所有算法的调用接口都接受 shape [n_samples, n_features] 的标准数据矩阵。 这些矩阵可以通过使用 sklearn.feature_extraction 模块中的类获得。对于 AffinityPropagation, SpectralClustering 和 DBSC...




