
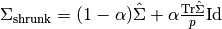
25
# 2.6. 协方差估计 校验者: [@李昊伟](https://github.com/apachecn/scikit-learn-doc-zh) [@小瑶](https://github.com/apachecn/scikit-learn-doc-zh) [@Loopy](https://github.com/loopyme) [@barrycg](https://github.com/barrycg) 翻译者: [@柠檬](https://github.com/apachecn/scikit-learn-doc-zh) 许多统计问题需要估计一个总体的协方差矩阵,这可以看作是对数据集散点图形状的估计。大多数情况下,必须对某个样本进行这样的估计,当它的属性(如尺寸,结构,均匀性)对估计质量有重大影响时。*sklearn.covariance* 包的目的是提供一个能在各种设置下准确估计总体协方差矩阵的工具。 我们假设观察是独立的,相同分布的 (i.i.d.)。 ## 2.6.1. 经验协方差 ...
24
2.5. 分解成分中的信号(矩阵分解问题)校验者: @武器大师一个挑俩 @png @barrycg翻译者: @柠檬 @片刻 2.5.1. 主成分分析(PCA)2.5.1.1. 准确的PCA和概率解释(Exact PCA and probabilistic interpretation)PCA 用于对具有一组连续正交分量(Orthogonal component 译注: 或译为正交成分,下出现 成分 和 分量 是同意词)的多变量数据集进行方差最大化的分解。 在 scikit-learn 中, PCA 被实现为一个变换器对象, 通过 fit 方法可以拟合出 n 个成分, 并且可以将新的数据投影(project, 亦可理解为分解)到这些成分中。 在应用SVD(奇异值分解) 之前, PCA 是在为每个特征聚集而不是缩放输入数据。可选参数 whiten=True 使得可以将数据投影到奇异(singular)空间上,同时将每个成分缩放到单位方差。 如果下游模型对信号的各向同性作出强假设,这通常是有用的,例如,使用RBF内核...
26
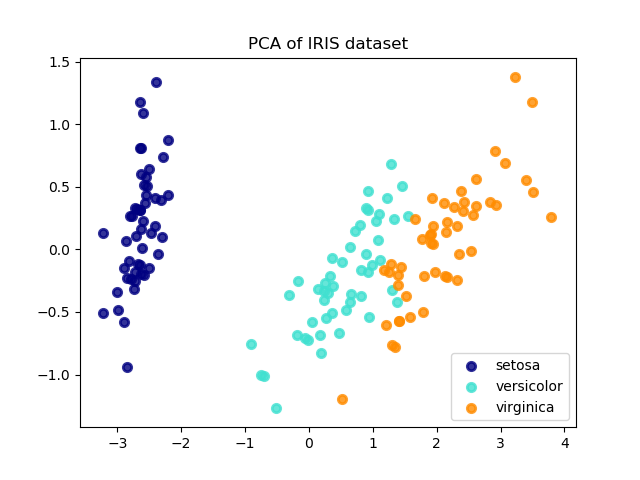
2.7. 新奇点和离群点检测校验者: @RyanZhiNie @羊三 @Loopy @barrycg翻译者: @羊三 许多应用程序需要能够对新观测值(observation 译注:观测到的样本的值 )进行判断,判断其是否与现有观测值服从同一分布(即新观测值为内围点(inlier)),相反则被认为不服从同一分布(即新观测值为离群点(outlier))。通常,这种能力被用于清理真实数据集, 但它有两种重要区分: 离群点检测: 训练数据包含离群点,即远离其它内围点。离群点检测估计器会尝试拟合出训练数据中内围点聚集的区域, 会忽略有偏离的观测值。 新奇点检测: 训练数据未被离群点污染,我们对新观测值是否为离群点感兴趣。在这个语境下,离群点被认为是新奇点。 离群点检测 和 新奇点检测 都被用于异常检测, 所谓异常检测就是检测反常的观测值或不平常的观测值。离群点检测 也被称之为 无监督异常检测; 而 新奇点检测 被称之为 半监督异常检测。 在离群点检测的语境下, 离群点/异常点 不能够形成一个稠密的聚类簇,...
27
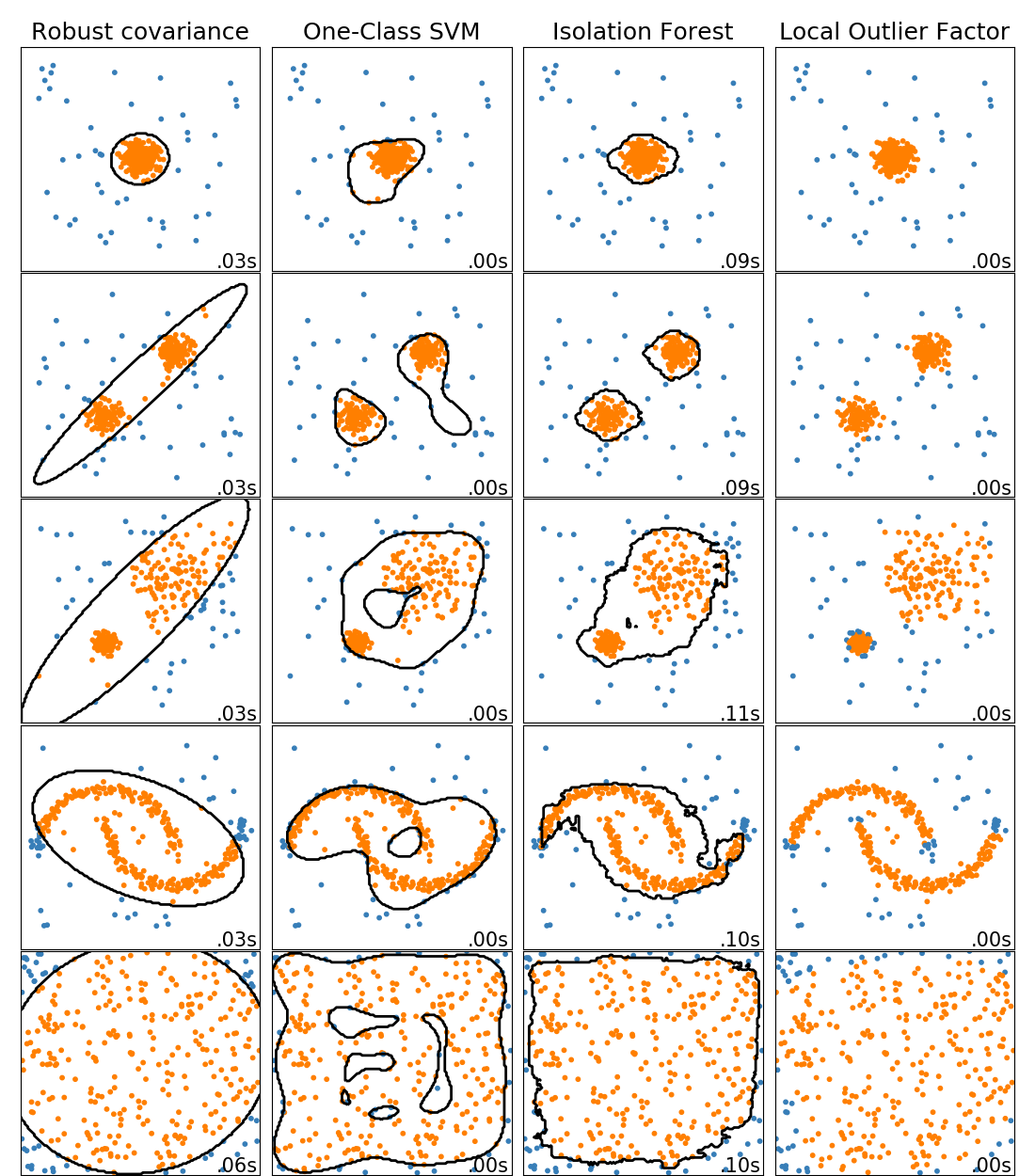
2.8. 密度估计校验者: @不将就 @barrycg翻译者: @Xi 密度估计涉及了无监督学习,特征工程和数据建模这三个不同的领域。一些最流行和最有用的密度估计方法是混合模型,如高斯混合( sklearn.mixture.GaussianMixture ), 和基于邻近的方法,如核密度估计sklearn.neighbors.KernelDensity。 clustering 一节中更充分地讨论了高斯混合,因为此方法也用作为一种无监督聚类方案。 密度估计是一个非常简单的概念,大多数人已经熟悉了其中一种常用的密度估计技术:直方图。 2.8.1. 密度估计: 直方图直方图是一种简单的数据可视化方法,其中定义了组( bins ),并且统计了每个组( bin )中的数据点的数量。在下图的左上角中可以看到一个直方图的示例: 然而,直方图的一个主要问题是分组( binning )的选择可能会对得到的可视化结果造成不相称的影响。考虑上图中右上角的图, 它显示了相同数据下,组( bins )向右移动后的直方图。这两个可视化的结果看起来完全不同,可能会导...

28
2.9. 神经网络模型(无监督)校验者: @不将就 @Loopy @barrycg @N!no翻译者: @夜神月 2.9.1. 限制波尔兹曼机限制玻尔兹曼机(Restricted Boltzmann machines,简称 RBM)是基于概率模型的无监督非线性特征学习器。当用 RBM 或多层次结构的RBMs 提取的特征在馈入线性分类器(如线性支持向量机或感知机)时通常会获得良好的结果。 该模型对输入的分布作出假设。目前,scikit-learn 只提供了 BernoulliRBM,它假定输入是二值(binary values)的,或者是 0 到 1 之间的值,每个值都编码特定特征被激活的概率。 RBM 尝试使用特定图形模型最大化数据的似然。它所使用的参数学习算法(随机最大似然)可以防止特征表示偏离输入数据。这使得它能捕获到有趣的特征,但使得该模型对于小数据集和密度估计不太有效。 该方法在初始化具有独立 RBM 权值的深度神经网络时得到了广泛的应用。这种方法是无监督的预训练。 示例: Restricted ...
30
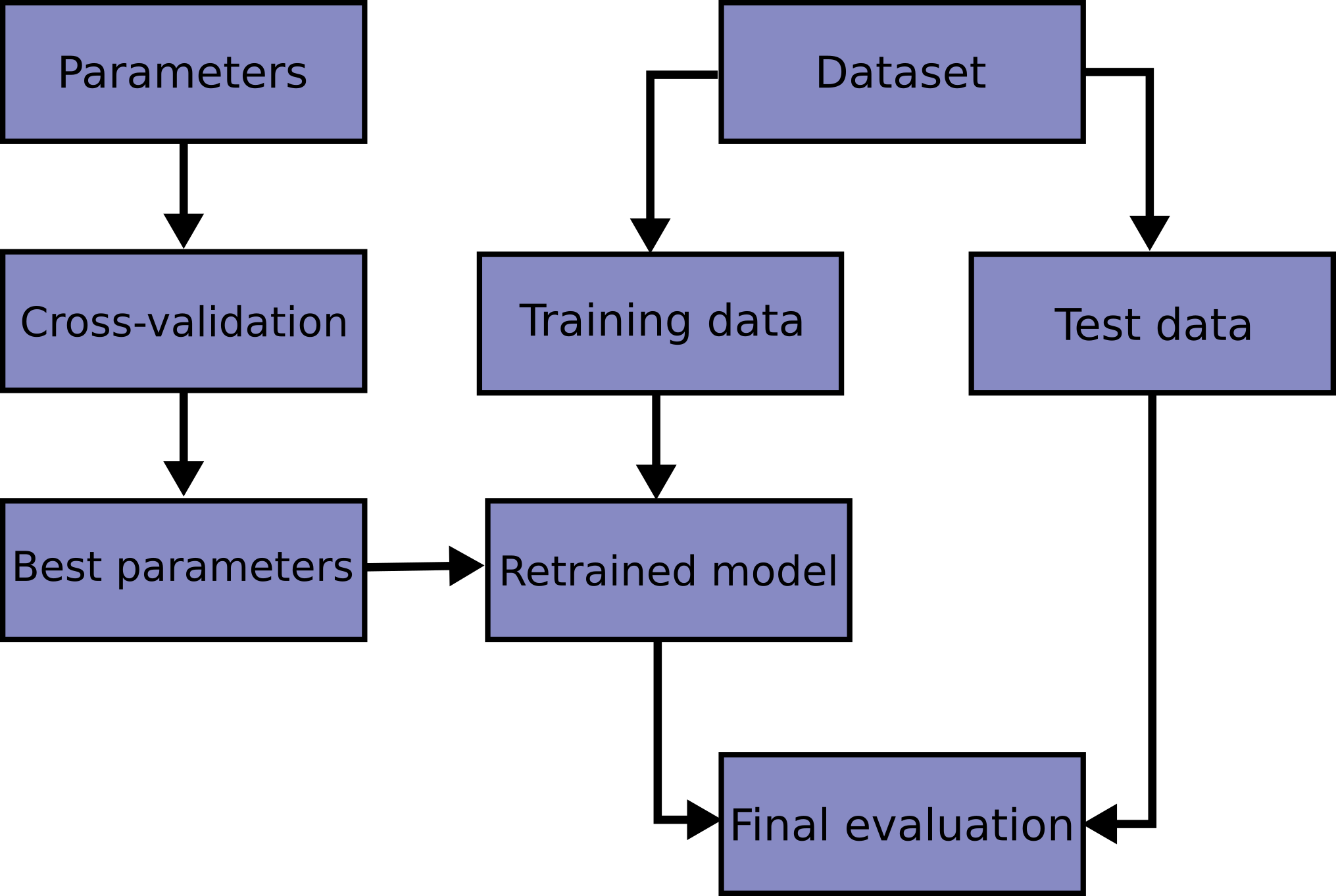
3.1. 交叉验证:评估估算器的表现校验者: @想和太阳肩并肩 @樊雯 @Loopy翻译者: @\S^R^Y/ 学习预测函数的参数,并在相同数据集上进行测试是一种错误的做法: 一个仅给出测试用例标签的模型将会获得极高的分数,但对于尚未出现过的数据它则无法预测出任何有用的信息。 这种情况称为 overfitting(过拟合). 为了避免这种情况,在进行(监督)机器学习实验时,通常取出部分可利用数据作为 test set(测试数据集) X_test, y_test。需要强调的是这里说的 “experiment(实验)” 并不仅限于学术(academic),因为即使是在商业场景下机器学习也往往是从实验开始的。下面是模型训练中典型的交叉验证工作流流程图。通过网格搜索可以确定最佳参数。 利用 scikit-learn 包中的 train_test_split 辅助函数可以很快地将实验数据集划分为任何训练集(training sets)和测试集(test sets)。 下面让我们载入 iris 数据集,并在此数据集上训练出线...

29
3. 模型选择和评估 3.1. 交叉验证:评估估算器的表现 3.1.1. 计算交叉验证的指标 3.1.2. 交叉验证迭代器 3.1.3. A note on shuffling 3.1.4. 交叉验证和模型选择 3.2. 调整估计器的超参数 3.2.1. 网格追踪法–穷尽的网格搜索 3.2.2. 随机参数优化 3.2.3. 参数搜索技巧 3.2.4. 暴力参数搜索的替代方案 3.3. 模型评估: 量化预测的质量 3.3.1. scoring 参数: 定义模型评估规则 3.3.2. 分类指标 3.3.3. 多标签排名指标 3.3.4. 回归指标 3.3.5. 聚类指标 3.3.6. 虚拟估计 3.4. 模型持久化 3.4.1. 持久化示例 3.4.2. 安全性和可维护性的局限性 3.5. 验证曲线: 绘制分数以评估模型 3.5.1. 验证曲线 3.5.2. 学习曲线
3
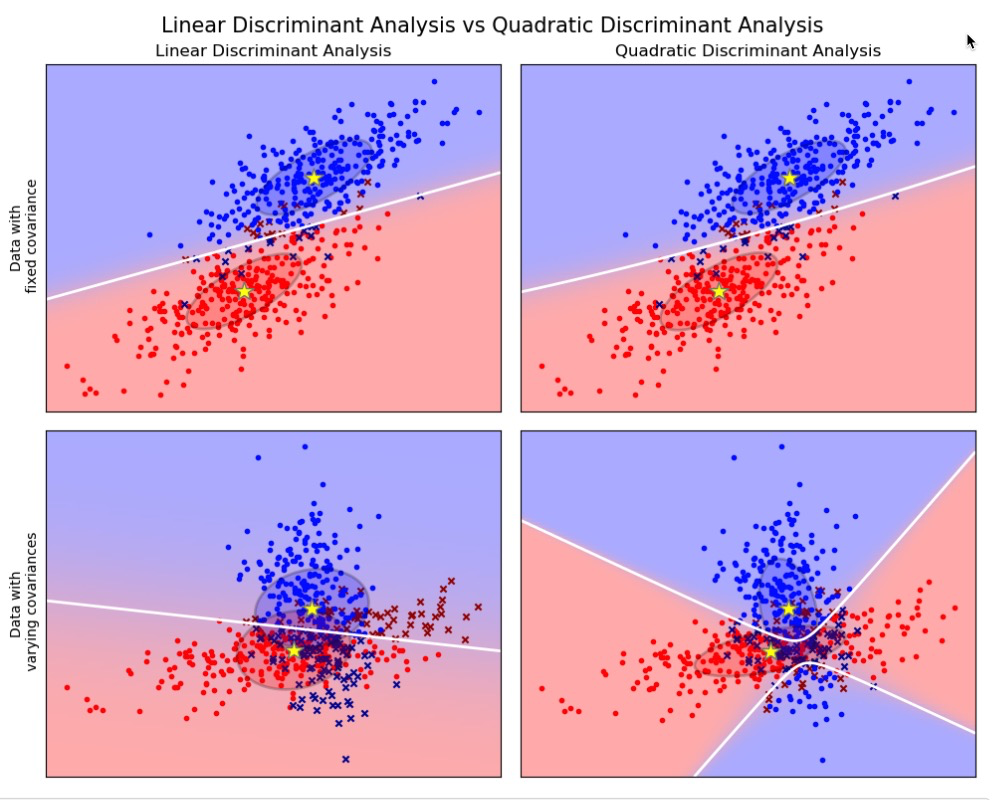
1.2. 线性和二次判别分析校验者: @AnybodyHome @numpy @Loopy @N!no翻译者: @FAME @N!no 线性判别分析(discriminant_analysis.LinearDiscriminantAnalysis)和二次判别分析(discriminant_analysis.QuadraticDiscriminantAnalysis)是两个经典的分类器。 正如他们名字所描述的那样,他们分别代表了线性决策平面和二次决策平面。 这些分类器十分具有吸引力,因为它们可以很容易计算得到闭式解(即解析解)。其本身具有多分类的特性,在实践中已经被证明很有效,而且无需调节超参数。 以上这些图像展示了线性判别分析以及二次判别分析的决策边界。其中,最后一行表明了线性判别分析只能学习线性边界, 而二次判别分析则可以学习二次边界,因此它相对而言更加灵活。 示例: Linear and Quadratic Discriminant Analysis with covariance el...

31
3.2. 调整估计器的超参数校验者: @想和太阳肩并肩翻译者: @\S^R^Y/ 超参数,即不直接在估计器内学习的参数。在 scikit-learn 包中,它们作为估计器类中构造函数的参数进行传递。典型的示例有:用于支持向量分类器的 C 、kernel 和 gamma ,用于Lasso的 alpha 等。 搜索超参数空间以便获得最好 交叉验证 分数的方法是可能的而且是值得提倡的。 通过这种方式,构造估计器时被提供的任何参数或许都能被优化。具体来说,要获取到给定估计器的所有参数的名称和当前值,使用: 1estimator.get_params() 搜索包括: 估计器(回归器或分类器,例如 sklearn.svm.SVC()) 参数空间 搜寻或采样候选的方法 交叉验证方案 计分函数 有些模型支持专业化的、高效的参数搜索策略, 描述如下 。在 scikit-learn 包中提供了两种采样搜索候选的通用方法:对于给定的值, GridSearchCV 考虑了所有参数组合;而 RandomizedSearchCV 可以从具有指定分布的参数空间中抽取...
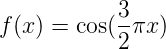
34
3.5. 验证曲线: 绘制分数以评估模型校验者: @正版乔 @正版乔 @小瑶翻译者: @Xi 每种估计器都有其优势和缺陷。它的泛化误差可以用偏差、方差和噪声来分解。估计值的 偏差 是不同训练集的平均误差。估计值的 方差 用来表示它对训练集的变化有多敏感。噪声是数据的一个属性。 在下面的图中,我们可以看到一个函数 和这个函数的一些噪声样本。 我们用三个不同的估计来拟合函数: 多项式特征为1,4和15的线性回归。我们看到,第一个估计最多只能为样本和真正的函数提供一个很差的拟合 ,因为它太简单了(高偏差),第二个估计几乎完全近似,最后一个估计完全接近训练数据, 但不能很好地拟合真实的函数,即对训练数据的变化(高方差)非常敏感。 偏差和方差是估计所固有的属性,我们通常必须选择合适的学习算法和超参数,以使得偏差和 方差都尽可能的低(参见偏差-方差困境)。 另一种降低方差的方法是使用更多的训练数据。不论如何,如果真实函数过于复杂并且不能用一个方 差较小的估计值来近似,则只能去收集更多的训练数据。 在一个简单的一维问题中,我们可以很容...




