

33
3.4. 模型持久化校验者: @why2lyj(Snow Wang) @小瑶翻译者: @那伊抹微笑 在训练完 scikit-learn 模型之后,最好有一种方法来将模型持久化以备将来使用,而无需重新训练。 以下部分为您提供了有关如何使用 pickle 来持久化模型的示例。 在使用 pickle 序列化时,我们还将回顾一些安全性和可维护性方面的问题。 pickle的另一种方法是使用相关项目中列出的模型导出工具之一将模型导出为另一种格式。与pickle不同,一旦导出,就不能恢复完整的Scikit-learn estimator对象,但是可以部署模型进行预测,通常可以使用支持开放模型交换格式的工具,如“ONNX”或“PMML”。 3.4.1. 持久化示例可以通过使用 Python 的内置持久化模型将训练好的模型保存在 scikit 中,它名为 pickle: 12345678910111213141516171819>>> from sklearn import svm>>> from sklearn imp...
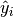
32
3.3. 模型评估: 量化预测的质量校验者: @飓风 @小瑶 @FAME @v @Loopy翻译者: @小瑶 @片刻 @那伊抹微笑 有 3 种不同的 API 用于评估模型预测的质量: Estimator score method(估计器得分的方法): Estimators(估计器)有一个 score(得分) 方法,为其解决的问题提供了默认的 evaluation criterion (评估标准)。 在这个页面上没有相关讨论,但是在每个 estimator (估计器)的文档中会有相关的讨论。 Scoring parameter(评分参数): Model-evaluation tools (模型评估工具)使用 cross-validation (如 model_selection.cross_val_score 和 model_selection.GridSearchCV) 依靠 internal scoring strategy (内部 scoring(得分) 策略)。...

35
4. 检验 4.1. 部分依赖图
36
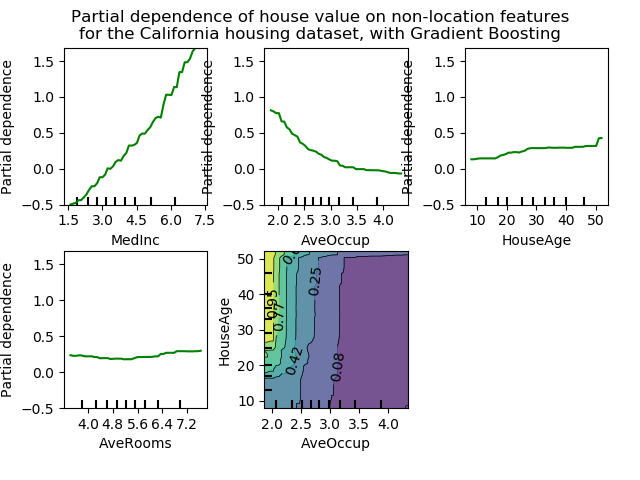
4.1. 部分依赖图校验者: 待核验翻译者: @Loopy 部分依赖图(以下简称PDP)显示了目标响应[1]和一组“目标”特征之间的依赖关系,并边缘化所有其他特征(特征补集,是目标特征集关于全部特征集合的补集)的值。直观地,我们可以将部分依赖关系解释为预期目标响应作为“目标”特征的函数。 由于人类感知的限制,目标特征集的大小必须很小(通常是一个或两个),因此目标特征通常需要从最重要的特征中选择。 下图展示了使用GradientBoostingRegressor实现的,加利福尼亚州住房数据集的四个单向和一个双向PDP: 单向PDP告诉我们目标响应和目标特征(如线性、非线性)之间的相互作用。上图左上方的图表显示了一个地区的收入中位数对房价中位数的影响;我们可以清楚地看到它们之间的线性关系。注意,PDP假设目标特征独立于补体特征,而这一假设在实践中经常被推翻。 具有两个目标特征的PDP显示了这两个特征之间的相互作用。例如,上图中的双变量PDP显示了房价中值与房屋年龄和每户平均居住者的联合值之间的关系。我们可以清楚地看到这两个特征之间的相互作用:对于平均入住...

37
5. 数据集转换scikit-learn 提供了一个用于转换数据集的库, 它也许会 clean(清理)(请参阅 预处理数据), reduce(减少)(请参阅 无监督降维), expand(扩展)(请参阅 内核近似)或 generate(生成)(请参阅 特征提取) feature representations(特征表示). 像其它预估计一样, 它们由具有 fit 方法的类来表示, 该方法从训练集学习模型参数(例如, 归一化的平均值和标准偏差)以及transform 方法将该转换模型应用于不可见数据. 同时 fit_transform 可以更方便和有效地建模与转换训练数据. 将 Pipeline(管道)和 FeatureUnion(特征联合): 合并的评估器 中 transformers(转换)使用并行的或者串联的方式合并到一起. 成对的矩阵, 类别和核函数 涵盖将特征空间转换为 affinity matrices(亲和矩阵), 而 预测目标 (y) 的转换 考虑在 scikit-learn 中使用目标空间的转换(例如. 标签分类). 5.1. Pipeline(管道)和 Fea...

38
5.1. Pipeline(管道)和 FeatureUnion(特征联合): 合并的评估器校验者: @程威 @Loopy翻译者: @Sehriff 变换器(Transformers)通常与分类器,回归器或其他的学习器组合在一起以构建复合估计器。 完成这件事的最常用工具是 Pipeline。 Pipeline 经常与 FeatureUnion 结合起来使用。 FeatureUnion 用于将变换器(transformers)的输出串联到复合特征空间(composite feature space)中。 TransformedTargetRegressor 用来处理变换 target (即对数变化 y)。 作为对比,Pipelines类只用来变换(transform)观测数据(X)。 5.1.1. Pipeline: 链式评估器 Pipeline 可以把多个评估器链接成一个。这个是很有用的,因为处理数据的步骤一般都是固定的,例如特征选择、标准化和分类。Pipeline 在这里有多种用途: 便捷性和封装性 你只要对数据调用 fit和 pred...
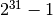
39
5.2. 特征提取校验者: @if only翻译者: @片刻 模块 sklearn.feature_extraction 可用于提取符合机器学习算法支持的特征,比如文本和图片。 注意特征特征提取与特征选择有很大的不同:前者包括将任意数据(如文本或图像)转换为可用于机器学习的数值特征。后者是将这些特征应用到机器学习中。 5.2.1. 从字典类型加载特征类 DictVectorizer 可用于将标准的Python字典(dict)对象列表的要素数组转换为 scikit-learn 估计器使用的 NumPy/SciPy 表示形式。 虽然 Python 的处理速度不是特别快,但 Python 的 dict 优点是使用方便,稀疏(不需要存储的特征),并且除了值之外还存储特征名称。 类 DictVectorizer 实现了 “one-of-K” 或 “one-hot” 编码,用于分类(也称为标称,离散)特征。分类功能是 “属性值” 对,其中该值被限制为不排序的可能性的离散列表(例如主题标识符,对象类型,标签,名称…)。 在下面的示例,”城市” 是一个分...
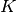
40
5.3 预处理数据校验者: @if only翻译者: @Trembleguy sklearn.preprocessing 包提供了几个常见的实用功能和变换器类型,用来将原始特征向量更改为更适合机器学习模型的形式。 一般来说,机器学习算法受益于数据集的标准化。如果数据集中存在一些离群值,那么稳定的缩放或转换更合适。不同缩放、转换以及归一在一个包含边缘离群值的数据集中的表现在 Compare the effect of different scalers on data with outliers 中有着重说明。 5.3.1 标准化,也称去均值和方差按比例缩放数据集的 标准化 对scikit-learn中实现的大多数机器学习算法来说是 常见的要求 。如果个别特征或多或少看起来不是很像标准正态分布(具有零均值和单位方差),那么它们的表现力可能会较差。 在实际情况中,我们经常忽略特征的分布形状,直接经过去均值来对某个特征进行中心化,再通过除以非常量特征(non-constant features)的标准差进行缩放。 例如,在机器学习算法的目标函数(例如SVM的...

41
5.4 缺失值插补校验者: @if only 待二次校验翻译者: @Trembleguy @Loopy 因为各种各样的原因,真实世界中的许多数据集都包含缺失数据,这类数据经常被编码成空格、NaNs,或者是其他的占位符。但是这样的数据集并不能scikit-learn学习算法兼容,因为大多的学习算法都默认假设数组中的元素都是数值,因而所有的元素都有自己的意义。 使用不完整的数据集的一个基本策略就是舍弃掉整行或整列包含缺失值的数据。但是这样就付出了舍弃可能有价值数据(即使是不完整的 )的代价。 处理缺失数值的一个更好的策略就是从已有的数据推断出缺失的数值。有关插补(imputation),请参阅常用术语表和API元素条目。 5.4.1 单变量与多变量插补一种类型的插补算法是单变量算法,它只使用第i个特征维度中的非缺失值(如impute.SimpleImputer)来插补第i个特征维中的值。相比之下,多变量插补算法使用整个可用特征维度来估计缺失的值(如impute.IterativeImputer)。 5.4.2 单变量插补Simp...

4
1.3. 内核岭回归校验者: @不吃曲奇的趣多多 @Loopy @qinhanmin2014翻译者: @Counting stars 内核岭回归(Kernel ridge regression-KRR)[1] 由使用内核方法的岭回归(使用 l2 正则化的最小二乘法)所组成。因此,它所拟合到的在空间中不同的线性函数是由不同的内核和数据所导致的。对于非线性的内核,它与原始空间中的非线性函数相对应。 由 KernelRidge 学习的模型的形式与支持向量回归( SVR 是一样的。但是他们使用不同的损失函数:内核岭回归(KRR)使用 squared error loss (平方误差损失函数)而 support vector regression (支持向量回归)(SVR)使用 -insensitive loss ( ε-不敏感损失 ),两者都使用 l2 regularization (l2 正则化)。与SVR 相反,拟合 KernelRidge 可以以 closed-form (封闭形式)完成,对于中型数据集通常更快。另一方面,学习...




