

42
5.5. 无监督降维校验者: @程威翻译者: @十四号 如果你的特征数量很多, 在监督步骤之前, 可以通过无监督的步骤来减少特征. 很多的 无监督学习 方法实现了一个名为 transform 的方法, 它可以用来降低维度. 下面我们将讨论大量使用这种模式的两个具体示例. Pipelining非监督数据约简和监督估计器可以链接起来。 请看 Pipeline: 链式评估器. 5.5.1. PCA: 主成份分析decomposition.PCA 寻找能够捕捉原始特征的差异的特征的组合. 请参阅 分解成分中的信号(矩阵分解问题). 示例 Faces recognition example using eigenfaces and SVMs 5.5.2. 随机投影模块: random_projection 提供了几种用于通过随机投影减少数据的工具. 请参阅文档的相关部分: 随机投影. 示例 The Johnson-Lindenstrauss bound for embedding with random projections 5.5.3. ...
44
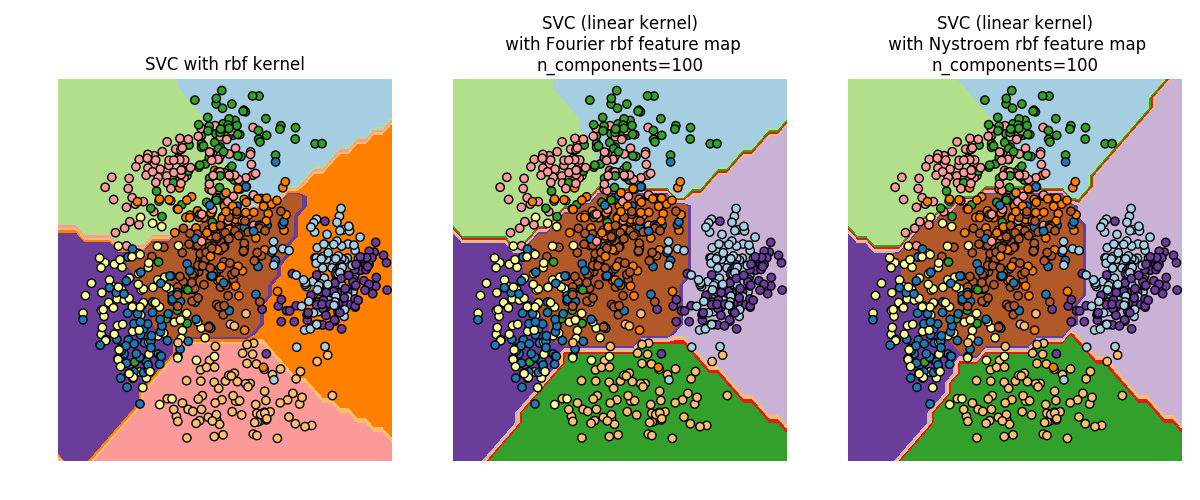
5.7. 内核近似校验者: @FontTian @numpy @Loopy翻译者: @程威 这个子模块包含与某些 kernel 对应的特征映射的函数,这个会用于例如支持向量机的算法当中(see 支持向量机)。 下面这些特征函数对输入执行非线性转换,可以用于线性分类或者其他算法。 与 kernel trick 相比,近似的进行特征映射更适合在线学习,并能够有效 减少学习大量数据的内存开销。使用标准核技巧的 svm 不能有效的适用到海量数据,但是使用近似内核映射的方法,对于线性 SVM 来说效果可能更好。 而且,使用 SGDClassifier 进行近似的内核映射,使得对海量数据进行非线性学习也成为了可能。 由于近似嵌入的方法没有太多经验性的验证,所以建议将结果和使用精确的内核方法的结果进行比较。 也可参阅多项式回归:用基函数展开线性模型 用于精确的多项式变换。 5.7.1. 内核近似的 Nystroem 方法Nystroem 中实现了 Nystroem 方法用于低等级的近似核。它是通过采样 kernel 已经评估好的数据。默认...
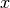
45
5.8. 成对的矩阵, 类别和核函数校验者: @FontTian @numpy翻译者: @程威 The sklearn.metrics.pairwise 子模块实现了用于评估成对距离或样本集合之间的联系的实用程序。 本模块同时包含距离度量和核函数,对于这两者这里提供一个简短的总结。 距离度量是形如 d(a, b) 例如 d(a, b) < d(a, c) 如果对象 a 和 b 被认为 “更加相似” 相比于 a 和 c. 两个完全相同的目标的距离是零。最广泛使用的示例就是欧几里得距离。 为了保证是 ‘真实的’ 度量, 其必须满足以下条件: 对于所有的 a 和 b,d(a, b) >= 0 正定性:当且仅当 a = b时,d(a, b) == 0 对称性:d(a, b) == d(b, a) 三角不等式:d(a, c) <= d(a, b) + d(b, c) 核函数是相似度的标准. 如果对象 a 和 b 被认为 “更加相似” 相比对象 a...
43
5.6. 随机投影校验者: @FontTian @程威翻译者: @Sehriff sklearn.random_projection 模块实现了一个简单且高效率的计算方式来减少数据维度,通过牺牲一定的精度(作为附加变量)来加速处理时间及更小的模型尺寸。 这个模型实现了两类无结构化的随机矩阵: Gaussian random matrix 和 sparse random matrix. 随机投影矩阵的维度和分布是受控制的,所以可以保存任意两个数据集的距离。因此随机投影适用于基于距离的方法。 参考资料: Sanjoy Dasgupta. 2000. Experiments with random projection. In Proceedings of the Sixteenth conference on Uncertainty in artificial intelligence (UAI‘00), Craig Boutilier and Moisés Goldszmidt (Eds.). Morgan Kaufmann Publi...

46
5.9. 预测目标 (y) 的转换校验者: @FontTian @numpy翻译者: @程威 本章要介绍的这些变换器不是被用于特征的,而是只被用于变换监督学习的目标。 如果你希望变换预测目标以进行学习,但是在原始空间中评估模型,请参考回归中的目标转换 。 5.9.1. 标签二值化LabelBinarizer 是一个用来从多类别列表创建标签矩阵的工具类: 12345678910>>> from sklearn import preprocessing>>> lb = preprocessing.LabelBinarizer()>>> lb.fit([1, 2, 6, 4, 2])LabelBinarizer(neg_label=0, pos_label=1, sparse_output=False)>>> lb.classes_array([1, 2, 4, 6])>>> lb.transform([1, 6])array([[1, 0, 0, 0],...
47
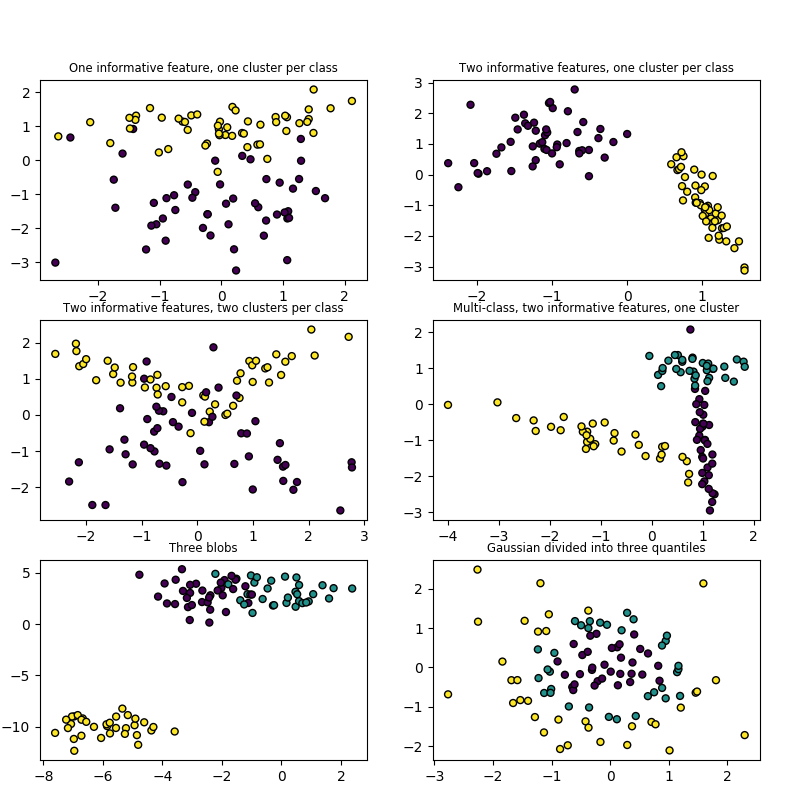
6. 数据集加载工具校验者: @不吃曲奇的趣多多 @A @火星 @Trembleguy @Loopy @mahaoyang翻译者: @cowboy @peels @t9UhoI @Sun 该 sklearn.datasets 包装在 入门指南 部分中嵌入了介绍一些小型玩具的数据集。 为了在控制数据的统计特性(通常是特征的 correlation (相关性)和 informativeness (信息性))的同时评估数据集 (n_samples 和 n_features) 的规模的影响,也可以生成综合数据。 这个软件包还具有帮助用户获取更大的数据集的功能,这些数据集通常由机器学习社区使用,用于对来自 ‘real world’ 的数据进行检测算法。 6.1. 通用数据集 API根据所需数据集的类型,有三种主要类型的数据集API接口可用于获取数据集。 loaders 可用来加载小的标准数据集,在玩具数据集中有介绍。 fetchers 可用来下载并加...
48
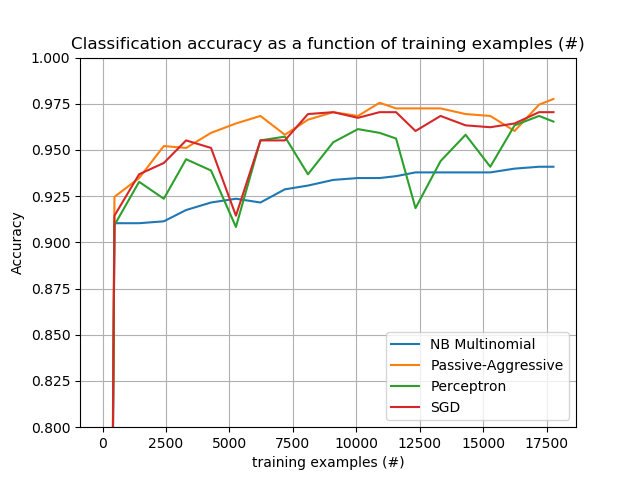
7. 使用scikit-learn计算7.1. 大规模计算的策略: 更大量的数据校验者: @文谊翻译者: @ゞFingヤ 对于一些应用程序,需要被处理的样本数量,特征数量(或两者)和/或速度这些对传统的方法而言非常具有挑战性。在这些情况下,scikit-learn 有许多你值得考虑的选项可以使你的系统规模化。 7.1.1. 使用外核学习实例进行拓展外核(或者称作 “外部存储器”)学习是一种用于学习那些无法装进计算机主存储(RAM)的数据的技术。 这里描述了一种为了实现这一目的而设计的系统: 一种用流来传输实例的方式 一种从实例中提取特征的方法 增量式算法 7.1.1.1. 流式实例基本上, 1. 可能是从硬盘、数据库、网络流等文件中产生实例的读取器。然而,关于如何实现的相关细节已经超出了本文档的讨论范围。 7.1.1.2. 提取特征 可以是 scikit-learn 支持的的不同 特征提取 <feature_extraction> 方法中的任何相关的方法。然而,当处理那些需要矢量化并且特征或值的集合你预先不知道的时候,就得明确...

50
scikit-learn 教程 0.21.x 使用 scikit-learn 介绍机器学习 机器学习:问题设置 加载示例数据集 学习和预测 模型持久化 规定 关于科学数据处理的统计学习教程 机器学习: scikit-learn 中的设置以及预估对象 数据集 预估对象 监督学习:从高维观察预测输出变量 最近邻和维度惩罚 线性模型:从回归到稀疏 支持向量机(SVMs) 模型选择:选择估计量及其参数 分数和交叉验证分数 交叉验证生成器 网格搜索和交叉验证估计量 无监督学习: 寻求数据表示 聚类: 对样本数据进行分组 分解: 将一个信号转换成多个成份并且加载 把它们放在一起 模型管道化 用特征面进行人脸识别 开放性问题: 股票市场结构 寻求帮助 项目邮件列表 机器学习从业者的 Q&A 社区 处理文本数据 教程设置 加载这 20 个新闻组的数据集 从文本文件中提取特征 训练分类器 构建-pipeline(管道) 在测试集上的性能评估 使用网格搜索进行调参 练习 快速链接 选择正确的评估器(estimator.md) 外部资源,视频和谈话
5
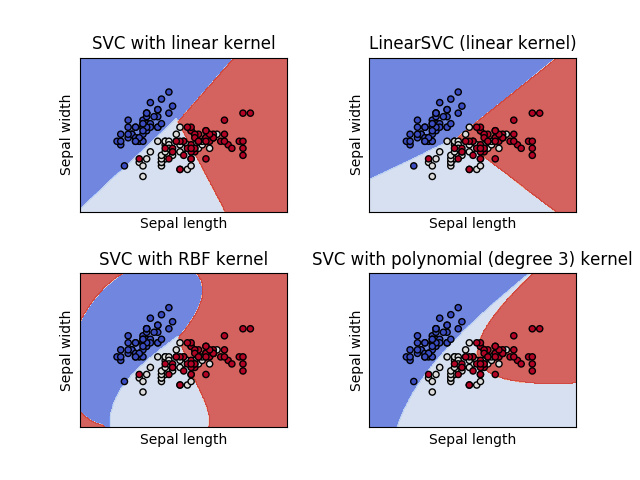
1.4. 支持向量机校验者: @尔了个达 @维 @子浪 @小瑶 @Loopy @qinhanmin2014翻译者: @Damon @Leon晋 支持向量机 (SVMs) 可用于以下监督学习算法: 分类, 回归 和 异常检测. 支持向量机的优势在于: 在高维空间中非常高效. 即使在数据维度比样本数量大的情况下仍然有效. 在决策函数(称为支持向量)中使用训练集的子集,因此它也是高效利用内存的. 通用性: 不同的核函数 核函数 与特定的决策函数一一对应.常见的 kernel 已经提供,也可以指定定制的内核. 支持向量机的缺点包括: 如果特征数量比样本数量大得多,在选择核函数 核函数 时要避免过拟合, 而且正则化项是非常重要的. 支持向量机不直接提供概率估计,这些都是使用昂贵的五次交叉验算计算的. (详情见 得分和概率). 在 scikit-learn 中,支持向量机提供 dense(numpy.ndarray ,可以通过 numpy.asarray 进行转换) 和...

52
关于科学数据处理的统计学习教程校验者: 待校验翻译者: @Loopy 统计学习 随着科学实验数据集规模的快速增长,机器学习机器学习技术正变得越来越重要。它能处理的问题主要包括:建立连接不同观测值的预测函数,对观测值进行分类,或者分析未标记数据集中的结构。 本教程将探讨统计学习。以统计推断为目标,使用机器学习技术,根据手头的数据来得出结论。 Scikit-learn是一个Python模块,它将科学计算的Python包(NumPy, SciPy, matplotlib)集成到了一起。 机器学习: scikit-learn 中的设置以及预估对象 数据集 预估对象 监督学习:从高维观察预测输出变量 最近邻和维度惩罚 线性模型:从回归到稀疏 支持向量机(SVMs) 模型选择:选择估计量及其参数 分数和交叉验证分数 交叉验证生成器 网格搜索和交叉验证估计量 无监督学习: 寻求数据表示 聚类: 对样本数据进行分组 分解: 将一个信号转换成多个成份并且加载 把它们放在一起 模型管道化 用特征面进行人脸识别 开放性问题: 股票市场结构 寻求帮助...



