
51
使用 scikit-learn 介绍机器学习校验者: @小瑶 @hlxstc @BWM-蜜蜂 @小瑶 @Loopy翻译者: @李昊伟 @… 内容提要 在本节中,我们介绍一些在使用 scikit-learn 过程中用到的 机器学习 词汇,并且给出一些示例阐释它们。 机器学习:问题设置一般来说,一个学习问题通常会考虑一系列 n 个 样本 数据,然后尝试预测未知数据的属性。 如果每个样本是 多个属性的数据 (比如说是一个多维记录),就说它有许多“属性”,或称 features(特征) 。 我们可以将学习问题分为几大类: 监督学习 , 其中数据带有一个附加属性,即我们想要预测的结果值( 点击此处 转到 scikit-learn 监督学习页面)。这个问题可以是: 分类 : 样本属于两个或更多个类,我们想从已经标记的数据中学习如何预测未标记数据的类别。 分类问题的一个示例是手写数字识别,其目的是将每个输入向量分配给有限数目的离散类别之一。 我们通常把分类视作监督学习的一个离散形式(区别于连续...
53
机器学习: scikit-learn 中的设置以及预估对象校验者: @Kyrie @片刻翻译者: @冰块 数据集Scikit-learn可以从一个或者多个数据集中学习信息,这些数据集合可表示为2维阵列,也可认为是一个列表。列表的第一个维度代表 样本 ,第二个维度代表 特征 (每一行代表一个样本,每一列代表一种特征)。 样例: iris 数据集(鸢尾花卉数据集) 12345>>> from sklearn import datasets>>> iris = datasets.load_iris()>>> data = iris.data>>> data.shape(150, 4) 这个数据集包含150个样本,每个样本包含4个特征:花萼长度,花萼宽度,花瓣长度,花瓣宽度,详细数据可以通过iris.DESCR查看。 如果原始数据不是(n_samples, n_features)的形状时,使用之前需要进行预处理以供scikit-learn使用。 数据预处理样例:dig...
54
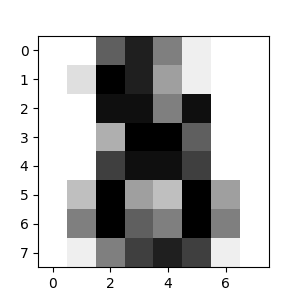
监督学习:从高维观察预测输出变量校验者: @Kyrie @片刻 @Loopy @N!no翻译者: @森系 监督学习解决的问题 监督学习 在于学习两个数据集的联系:观察数据 X 和我们正在尝试预测的额外变量 y (通常称“目标”或“标签”), 而且通常是长度为 n_samples 的一维数组。 scikit-learn 中所有监督的估计量 都有一个用来拟合模型的 fit(X, y) 方法,和根据给定的没有标签观察值 X 返回预测的带标签的 y 的 predict(X) 方法。 词汇:分类和回归 如果预测任务是为了将观察值分类到有限的标签集合中,换句话说,就是给观察对象命名,那任务就被称为 分类 任务。另外,如果任务是为了预测一个连续的目标变量,那就被称为 回归 任务。 当在 scikit-learn 中进行分类时,y 是一个整数或字符型的向量。 注:可以查看用 scikit-learn 进行机器学习介绍 快速了解机器学习中的基础词汇。 最近邻和维度惩罚 鸢尾属植物分类 鸢尾属植物数据集是根据花瓣长度...
56
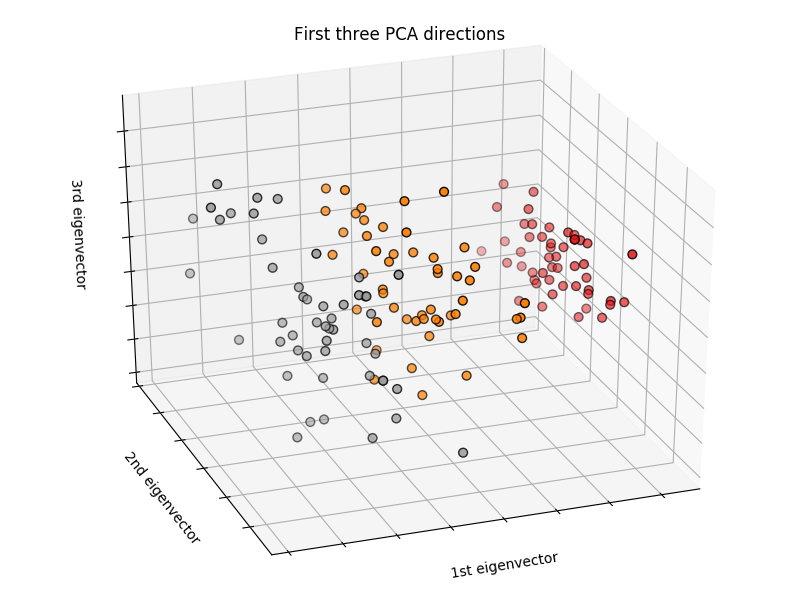
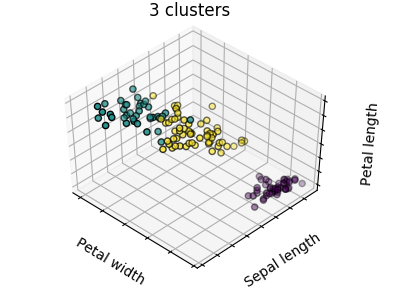
无监督学习: 寻求数据表示校验者: @片刻翻译者: @X 聚类: 对样本数据进行分组 可以利用聚类解决的问题 对于 iris 数据集来说,我们知道所有样本有 3 种不同的类型,但是并不知道每一个样本是那种类型:此时我们可以尝试一个 clustering task(聚类任务) 聚类算法: 将样本进行分组,相似的样本被聚在一起,而不同组别之间的样本是有明显区别的,这样的分组方式就是 clusters(聚类) K-means 聚类算法关于聚类有很多不同的聚类标准和相关算法,其中最简便的算法是 K-means 。 12345678910111213>>> from sklearn import cluster, datasets>>> iris = datasets.load_iris()>>> X_iris = iris.data>>> y_iris = iris.target>>> k_means = cluster.KMeans(n_clusters=3)>...
55
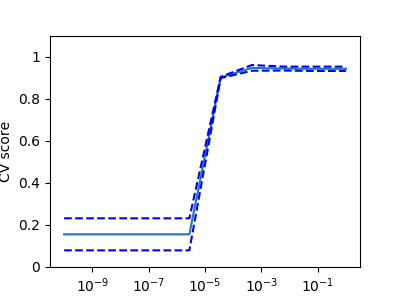
模型选择:选择估计量及其参数校验者: @片刻翻译者: @森系 分数和交叉验证分数如我们所见,每一个估计量都有一个可以在新数据上判定拟合质量(或预期值)的 score 方法。越大越好. 1234567>>> from sklearn import datasets, svm>>> digits = datasets.load_digits()>>> X_digits = digits.data>>> y_digits = digits.target>>> svc = svm.SVC(C=1, kernel='linear')>>> svc.fit(X_digits[:-100], y_digits[:-100]).score(X_digits[-100:], y_digits[-100:])0.98 为了更好地预测精度(我们可以用它作为模型的拟合优度代理),我们可以连续分解用于我们训练和测试用的 折叠数据。 123456789...
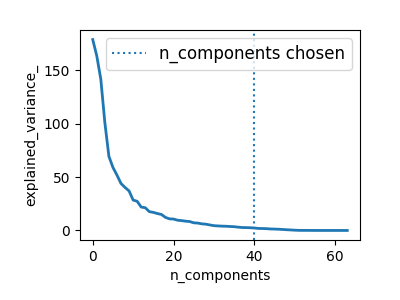
57
把它们放在一起校验者: @片刻翻译者: @X 模型管道化我们已经知道一些模型可以做数据转换,一些模型可以用来预测变量。我们可以建立一个组合模型同时完成以上工作: 1234567891011121314151617181920212223242526272829303132333435363738394041import numpy as npimport matplotlib.pyplot as pltimport pandas as pdfrom sklearn import datasetsfrom sklearn.decomposition import PCAfrom sklearn.linear_model import SGDClassifierfrom sklearn.pipeline import Pipelinefrom sklearn.model_selection import GridSearchCV# Define a pipeline to search for the best combination of PCA tr...

58
寻求帮助校验者: @片刻翻译者: @X 项目邮件列表如果您在使用 scikit 的过程中发现错误或者需要在说明文档中澄清的内容,可以随时通过 Mailing List 进行咨询。 机器学习从业者的 Q&A 社区 Quora.com: Quora有一个和机器学习问题相关的主题以及一些有趣的讨论: https://www.quora.com/topic/Machine-Learning Stack Exchange: Stack Exchange 系列网站包含 multiple subdomains for Machine Learning questions(机器学习问题的多个分支)_。 ’斯坦福大学教授 Andrew Ng 教授的机器学习优秀免费在线课程’: https://www.coursera.org/learn/machine-learning ’另一个优秀的免费在线课程,对人工智能采取更一般的方法’: https://www.udacity.com/course/intro-to-artificial-intelli...

59
处理文本数据校验者: @NellyLuo @那伊抹微笑 @微光同尘翻译者: @Lielei 本指南旨在一个单独实际任务中探索一些主要的 scikit-learn 工具: 分析关于 20 个不同主题的一个文件集合(新闻组帖子)。 在本节中,我们将会学习如何: 读取文件内容以及所属的类别 提取合适于机器学习的特征向量 训练一个线性模型来进行分类 使用网格搜索策略找到特征提取组件和分类器的最佳配置 教程设置开始这篇教程之前,你必须首先安装 scikit-learn 以及所有其要求的库。 更多信息和系统安装指导请参考 安装说明 。 这篇入门教程的源代码可以在你的 scikit-learn 文件夹下面找到: 1scikit-learn/doc/tutorial/text_analytics/ 这个入门教程包含以下的子文件夹: *.rst files - 用 sphinx 编写的该教程的源代码 data - 用来存放在该教程中用到的数据集的文件夹 skeletons - 用来练习的未完成的示例脚本 solutions - 练习的...
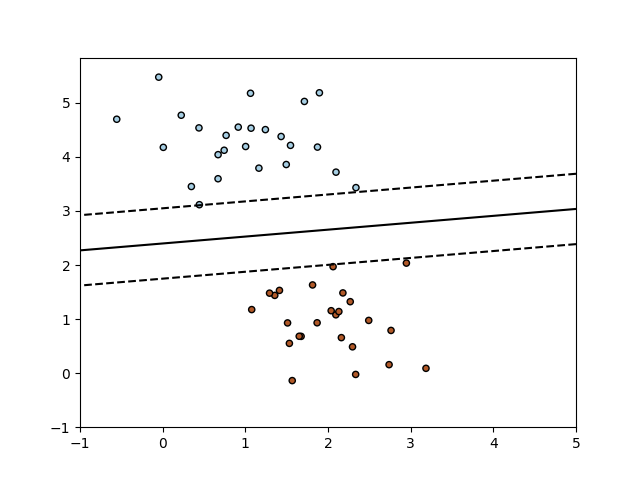
6
1.5. 随机梯度下降校验者: @A @HelloSilicat @Loopy @qinhanmin2014翻译者: @L 随机梯度下降(SGD) 是一种简单但又非常高效的方法,主要用于凸损失函数下线性分类器的判别式学习,例如(线性) 支持向量机 和 Logistic 回归 。 尽管 SGD 在机器学习社区已经存在了很长时间, 但是最近在 large-scale learning (大规模学习)方面 SGD 获得了相当大的关注。 SGD 已成功应用于在文本分类和自然语言处理中经常遇到的大规模和稀疏的机器学习问题。对于稀疏数据,本模块的分类器可以轻易的处理超过 10^5 的训练样本和超过 10^5 的特征。 Stochastic Gradient Descent (随机梯度下降法)的优势: 高效。 易于实现 (有大量优化代码的机会)。 Stochastic Gradient Descent (随机梯度下降法)的劣势: SGD 需要一些超参数,例如 regularization (正则化)参数和 number...
60
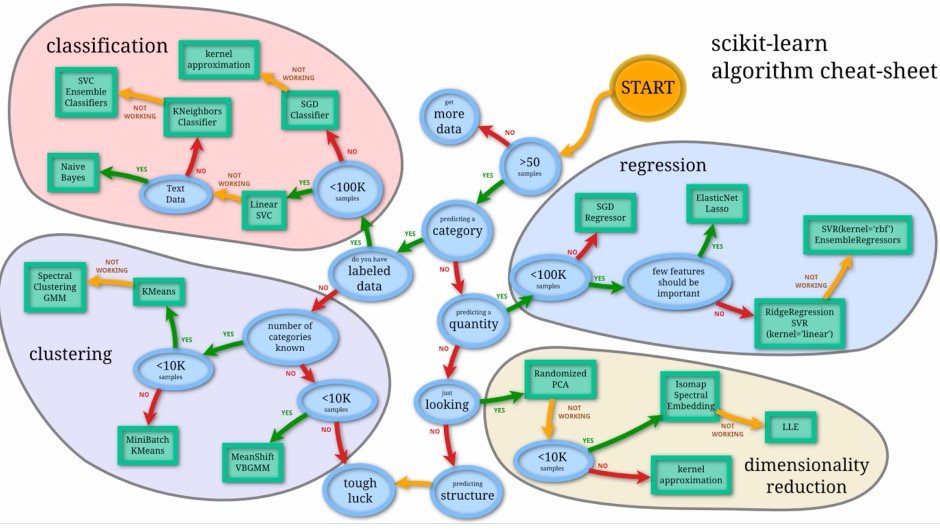
选择正确的评估器(estimator)校验者:翻译者: @李孟禹 通常,解决机器学习问题的最困难的部分可能是找到恰当的的评估器(estimator)。 不同的评估器更适合不同类型的数据和不同的问题。 下面的流程图是一些粗略的指导,可以让用户根据自己的数据来选择应该尝试哪些评估器。 点击下图的任何评估器,查看其文档。




