

61
外部资源,视频和谈话校验者: 翻译者: @巴黎灬メの雨季 For written tutorials, see the Tutorial section of the documentation. Scientific Python 的新手?For those that are still new to the scientific Python ecosystem, we highly recommend the Python Scientific Lecture Notes. This will help you find your footing a bit and will definitely improve your scikit-learn experience. A basic understanding of NumPy arrays is recommended to make the most of scikit-learn. 外部教程There are several online tutorials available which are ...

62
安装 scikit-learn校验者: @小瑶 @Loopy翻译者: @片刻 Note 如果你想为这个项目做出贡献,建议你 安装最新的开发版本 . 安装最新版本Scikit-learn 要求: Python (>= 3.5), NumPy (>= 1.11.0), SciPy (>= 0.17.0), joblib (>= 0.11). Scikit-learn绘图功能(即,函数以“plot_”开头,需要Matplotlib(>= 1.5.1)。一些scikit-learn示例可能需要一个或多个额外依赖项:scikit-image(>= 0.12.3)、panda(>= 0.18.0)。 警告: Scikit-learn 0.20是支持Python 2.7和Python 3.4的最后一个版本。Scikit-learn现在需要Python 3.5或更新版本。 如果你已经有一个合适的 numpy 和 scipy版本,安装...

64
时光轴详情该页面展示了本 scikit-learn 中文文档项目随时间变化,而发生的重大事情,特在该页面记录下来。 贡献者衷心感谢给位参与的贡献者,具体的贡献者列表,请参阅【0.19.X】贡献者名单. 项目角色有关该项目的角色角色信息,比如: 负责人,发起人,支持者,翻译者,校验者 。。。等等信息,请参阅项目角色结构. 时光轴2019-06-29: 更新用户指南和教程到0.21.3版本,修正格式问题,文档链接为:https://sklearn.apachecn.org/docs/0.21.3 2017-11-17: 更新校验完成的页面,修改文档样式,在对应的页面加上对应的贡献者,文档链接为:https://sklearn.apachecn.org/docs/0.19.x. 2017-10-20: 发起 scikit-learn 0.19 中文文档 的第一期校验活动,又来了一些新的大佬,参与到该活动中来,具体的校验详情请参阅校验进度. 2017-09-29: 发起 scikit-learn 0.19 中文文档 的翻译活动,有很多无私的贡献者愿意参与,具体的翻译详情请参阅翻译进度.

63
常见问题校验者: @Mysry翻译者: @STAN,废柴0.1 在这里,我们试着给出一些经常出现在邮件列表上的问题的答案。 项目名称是什么(很多人弄错)?scikit-learn, 不是scikik、SciKit、sci-kit learn,也不是我们曾使用的scikits.learn和scikits-learn。 如何称呼scikit-learn?sy-kit learn。sci代表着科学! 选择 scikit的理由 ?scikit拥有很多围绕Scipy构建的科学工具箱。你可以在 <https://scikits.appspot.com/scikits> 查找工具列表。 scikit-image <http://scikit-image.org/> 和 scikit-learn_一样受欢迎 。 如何才能为 scikit-learn 贡献自己的力量?在添加一个通常是重要冗长的新算法前, 推荐你观看 known issues 。 关于 scikit-learn 贡献,请不要直接和 scikit-learn 的贡献者联系。 获得sc...
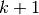
7
1.6. 最近邻sklearn.neighbors 提供了 neighbors-based (基于邻居的) 无监督学习以及监督学习方法的功能。 无监督的最近邻是许多其它学习方法的基础,尤其是 manifold learning (流形学习) 和 spectral clustering (谱聚类)。 neighbors-based (基于邻居的) 监督学习分为两种: classification (分类)针对的是具有离散标签的数据,regression (回归)针对的是具有连续标签的数据。 最近邻方法背后的原理是从训练样本中找到与新点在距离上最近的预定数量的几个点,然后从这些点中预测标签。 这些点的数量可以是用户自定义的常量(K-最近邻学习), 也可以根据不同的点的局部密度(基于半径的最近邻学习)确定。距离通常可以通过任何度量来衡量: standard Euclidean distance(标准欧式距离)是最常见的选择。Neighbors-based(基于邻居的)方法被称为 非泛化 机器学习方法, 因为它们只是简单地”记住”了其所有的训练数据(可能转换为一个快速索引结构,如 Bal...
8
1.7. 高斯过程校验者: @glassy @Trembleguy @Loopy翻译者: @AI追寻者 高斯过程 (GP) 是一种常用的监督学习方法,旨在解决回归问题和概率分类问题。 高斯过程模型的优点如下: 预测内插了观察结果(至少对于正则核)。 预测结果是概率形式的(高斯形式的)。这样的话,人们可以计算得到经验置信区间并且据此来判断是否需要修改(在线拟合,自适应)在一些区域的预测值。 通用性: 可以指定不同的:内核(kernels)。虽然该函数提供了常用的内核,但是也可以指定自定义内核。 高斯过程模型的缺点包括: 它们不稀疏,例如,模型通常使用整个样本/特征信息来进行预测。 高维空间模型会失效,高维也就是指特征的数量超过几十个。 1.7.1. 高斯过程回归(GPR)GaussianProcessRegressor 类实现了回归情况下的高斯过程(GP)模型。 为此,需要实现指定GP的先验。当参数 normalize_y=False 时,先验的均值 通常假定为常数或者零; 当 normalize_y=Tru...
9
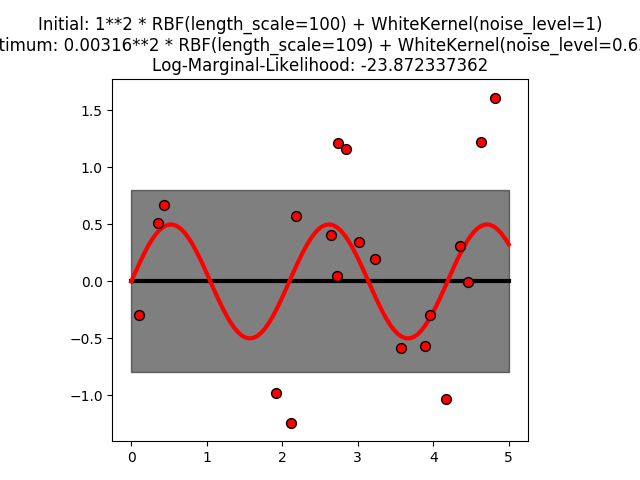
1.8. 交叉分解校验者: @peels @qinhanmin2014翻译者: @Counting stars 交叉分解模块主要包含两个算法族: 偏最小二乘法(PLS)和典型相关分析(CCA)。 这些算法族具有发现两个多元数据集之间的线性关系的用途: fit method (拟合方法)的参数 X 和 Y 都是 2 维数组。 交叉分解算法能够找到两个矩阵 (X 和 Y) 的基础关系。它们是对在两个空间的协方差结构进行建模的隐变量方法。它们将尝试在X空间中找到多维方向,该方向能够解释Y空间中最大多维方差方向。 PLS回归特别适用于当预测变量矩阵具有比观测值更多的变量以及当X值存在多重共线性时。相比之下,在这些情况下,标准回归将失败。 包含在此模块中的类有:PLSRegression, PLSCanonical, CCA, PLSSVD 参考资料: JA Wegelin A survey of Partial Least Squares (PLS) methods, with emphasis on the two-block case ...
a_demo_of_the_spectral_co-clustering_algorithm
频谱共聚算法演示 翻译者:@N!no校验者:待校验 这个例子演示了如何使用谱协聚类算法生成数据集并对其进行双聚类处理。 数据集是使用 make_biclusters 函数生成的,该函数创建一个小值矩阵,并将大值植入双聚类。然后将行和列打乱并传递给光谱协聚算法。通过重新排列变换后的矩阵可以使双聚类连续,这展示出该算法找到双聚类的准确性。 1consensus score: 1.0 123456789101112131415161718192021222324252627282930313233343536373839404142print(__doc__)# Author: Kemal Eren <kemal@kemaleren.com># License: BSD 3 clauseimport numpy as npfrom matplotlib import pyplot as pltfrom sklearn.datasets import make_biclustersfrom sklearn.cluster import SpectralCoclus...
a_demo_of_the_spectral_clustering_algorithm
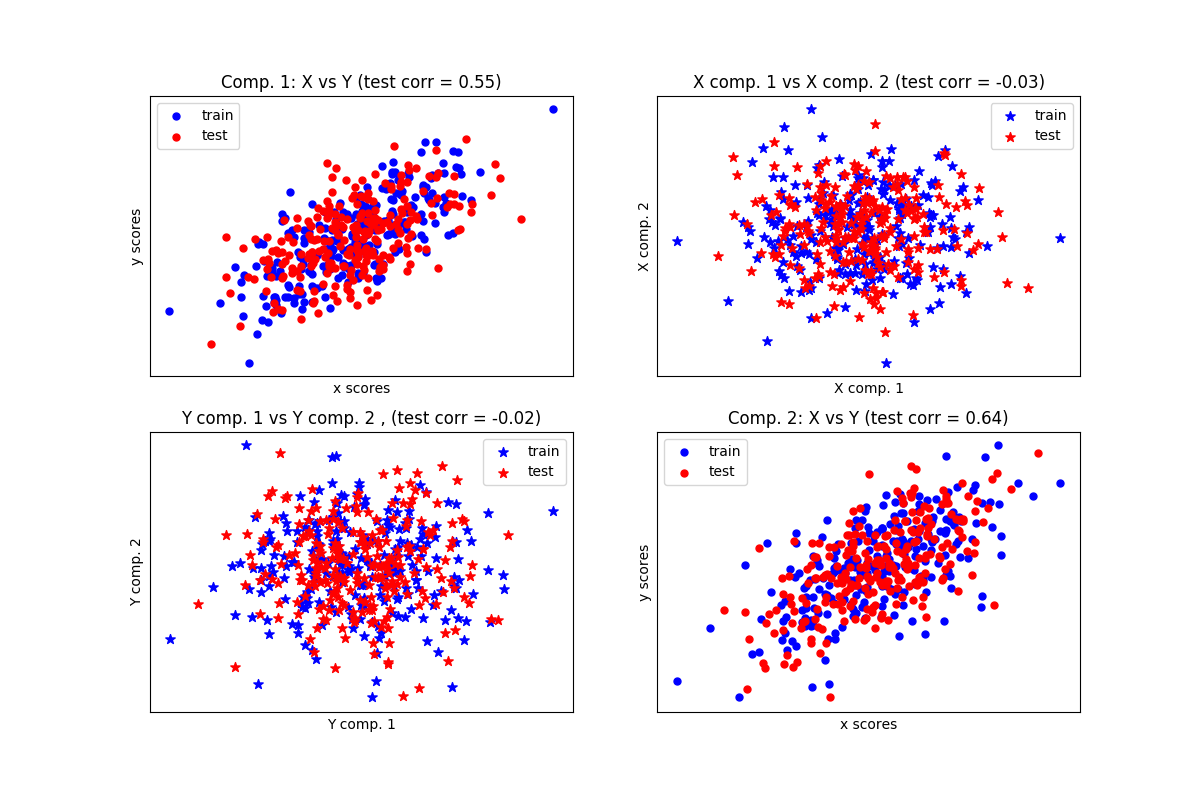
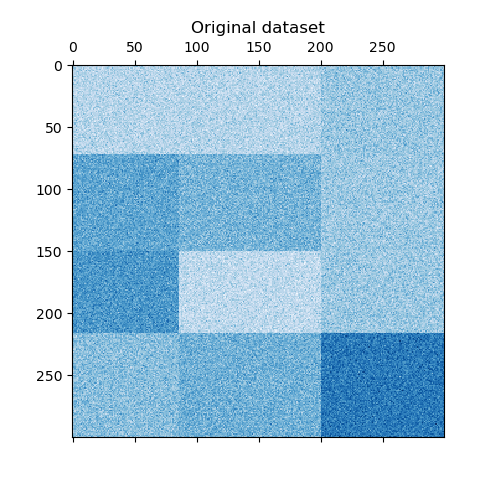
频谱双聚类算法演示 翻译者:@N!no校验者:待校验 这个例子演示了如何使用光谱聚类算法生成棋盘数据集并对其进行聚类处理。 数据是用make_checkerboard函数生成的,然后打乱顺序并传递给光谱双聚类算法。变换后的矩阵的行和列被重新排列,以显示该算法找到的双聚类。 行和列标签向量的外积表示棋盘结构。 1consensus score: 1.0 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950print(__doc__)# Author: Kemal Eren <kemal@kemaleren.com># License: BSD 3 clauseimport numpy as npfrom matplotlib import pyplot as pltfrom sklearn.datasets import make_checkerboardfrom sklearn.cluster import SpectralB...

biclustering_documents_with_the_spectral_co-clustering_algorithm
使用频谱共聚算法对文档进行聚合 翻译者:@N!no校验者:待校验 这个例子演示了20个新闻组数据集上的光谱协聚类算法。‘comp.os.ms-windows.misc’ 类别被排除在外,因为它包含许多只包含数据的帖子。 TF-IDF 矢量帖构成一个词频矩阵,然后使用 Dhillon 光谱协聚算法对其进行重组。由此产生的文档词双聚类表明在这些子集文档中被使用频率更高的子集词。 对于一些最好的双聚类来说,它最常见的文档类别和十个最重要的单词会被打印出来。最佳双类别由其归一化的切割决定。最好的单词是通过比较它们在两区内和两区外的总和来确定的。 为了进行比较,我们还使用 MiniBatchKMeans 对文档进行集群。从双聚类衍生出的文档聚类比使用 MiniBatchKMeans 得到的聚类具有更好的 V-measure。 123456789101112131415161718192021222324252627Vectorizing...Coclustering...Done in 2.75s. V-measure: 0.4387MiniBatchKMeans...Done in 5...




