

11 递归与迭代
递归与迭代。 参考文献 递归详解 递归算法讲解 递归算法的理解 递归的本质 由于递归与迭代的特殊性。在这里单独列出一种思想。递归与迭代思想,用来处理所有的重复的操作。如分治法的相同子操作、动态规划的相同子操作、深度优先搜索、广度优先搜索的相同子操作。 1 递归法概述基本思想 直接或间接的调用自身的算法称为递归算法。用函数自身给出定义的函数称为递归函数。 递归的基本思想就是把规模大的问题转化为规模小的相似的子问题来解决。 递归的数学模型其实就是数学归纳法。可以用反向递推式表示递归的过程。(使用正向递推式表示循环的过程) 线性收缩递归算法 递推关系式 $$T(n)=\begin{cases} o(1) & n=1 \ \sum_{i=1}^k a_iT(n-i)+f(n) & n>1\end{cases}$$ 求解递推关系式$$T(n)=a^{n-1}T(1)+\sum_{i=2}^na^{n-i}f(i)$$ 关系式说明 等比收缩递归算法 递推关系式$$T(n)=\be...

12 深搜与广搜
深度优先搜索与广度优先搜索 用来处理多分支结构 对于现行问题或单分支结构的问题。不适用深度搜索和广度搜索 1 深度搜索 深度优先搜索属于图算法的一种,是一个针对图和树的遍历算法,英文缩写为DFS即Depth First Search。深度优先搜索是图论中的经典算法,利用深度优先搜索算法可以产生目标图的相应拓扑排序表,利用拓扑排序表可以方便的解决很多相关的图论问题,如最大路径问题等等。一般用堆数据结构来辅助实现DFS算法。其过程简要来说是对每一个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次。 深度优先搜索与回溯剪枝这两个思想有一个非常重要的优势。它是一条路经走到黑。如果这条路径合适的话,就可以直接返回。另外。当前所有的搜索选项中,只有一条路径在工作。也就是说只需要记录当前一条路径的状态。所以解决迷宫问题的时候,不需要复杂的状态记录方法。只需要记录当前这一个分支的路径状态即可。 2 广度搜索 广度优先搜索(也称宽度优先搜索,缩写BFS,以下采用广度来描述)是连通图的一种遍历算法这一算法也是很多重要的图的算法的原型。Dijkstra单源最短路径算法和Prim最小生成...

说明
1 说明 依赖与特定数据结构的处理操作。

2.1 单链表
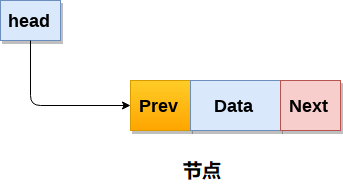
单链表1 简介概念 单链表是有序元素集的集合。元素的数量可以根据程序的需要而变化。 单链表中的节点由两部分组成:数据部分和链接部分。 节点的数据部分存储将由节点表示的实际信息,而节点的链接部分存储其直接后继的地址。 单向链或单链表可以仅在一个方向上遍历。也就是说每个节点只包含下一个节点的指针,因此不能反向遍历链表。 链表复杂度 操作 平均复杂度 最坏复杂度 访问 θ(n) θ(n) 搜索 θ(n) θ(n) 插入 θ(1) θ(1) 删除 θ(1) θ(1) 2 链表的存储和实现链表的存储 链表不需要连续存在于存储器中。节点可以是存储器中的任何位置并链接在一起以形成链表。这实现了空间的优化利用。 链表的实现 链表通过结构体和指针实现 1234567struct node { int data; struct node *next; }; struct node *head, *ptr; ptr = (struct node *)malloc(sizeof(struct node *)); ...
2.2 双链表
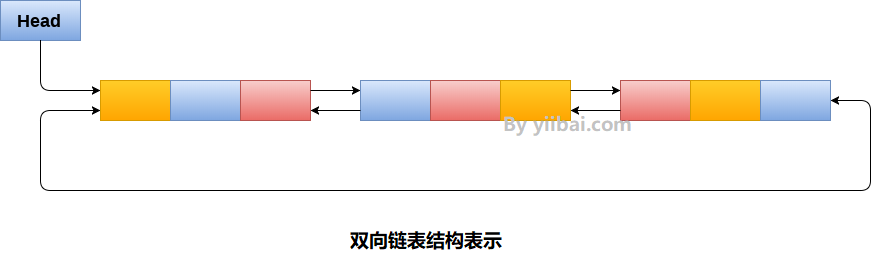
双链表1 双链表的简介概念 双向链表是一种复杂类型的链表,它的节点包含指向序列中前一个节点和下一个节点的指针。 在双向链表中,节点由三部分组成:节点数据,指向下一个节点的指针(next指针),指向前一个节点的指针(prev指针)。 2 双链表的存储和实现数据存储 双向链表为每个节点消耗更多空间 可以更灵活地操作链表中的元素。 数据实现 使用结构体和指针实现。 123456struct node { struct node *prev; int data; struct node *next; } 使用STL中的list实现 12#include<list>list<int> li; 3 双链表的操作基本操作 创建 遍历、搜索 插入 删除 实现12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656...
2.3 循环单链表
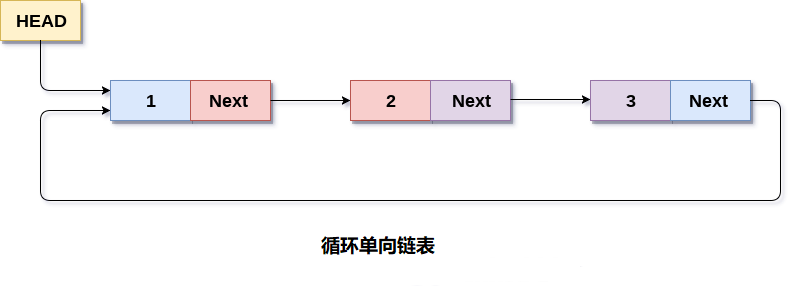
循环单向链表1 简介概念 在循环单链表中,链表的最后一个节点包含指向链表的第一个节点的指针。可以有循环单向链表以及循环双链表。 遍历一个循环单链表,直到到达开始的同一个节点。循环单链表类似于链表,但它没有开始也没有结束。任何节点的下一部分都不存在NULL值。 2 数据存储和实现数据存储链表的最后一个节点包含链表的第一个节点的地址。 数据实现 链表通过结构体和指针实现 1234567struct node { int data; struct node *next; }; struct node *head, *ptr; ptr = (struct node *)malloc(sizeof(struct node *)); C++ STL提供了链表的实现 1234#include<list>list<int> li;forward_list<int> li; 3 操作基本操作 创建 遍历、搜索 插入 删除 实现1234567891011121314151617181920212...
2.4 循环双链表
循环双向链表1 简介概念 循环双向链表是一种更复杂的数据结构类型,它的节点包含指向其前一节点以及下一节点的指针。 循环双向链表在任何节点中都不包含NULL。 链表的最后一个节点包含列表的第一个节点的地址。 链表的第一个节点还包含的前一个指针是指向最后一个节点的地址。 2 数据存储和实现数据存储 起始节点包含最后一个(也是前一个)节点的地址,即8和下一个节点,即4。链表的最后一个节点,存储在地址8并包含数据6,包含链表的第一个节点的地址 数据实现 使用结构体和指针实现。 123456struct node { struct node *prev; int data; struct node *next; } 使用STL中的list实现 12#include<list>list<int> li; 3 操作基本操作 创建 遍历、搜索 插入 删除 实现1234567891011121314151617181920212223242526272829303132333435363738394...
4.1 循环队列
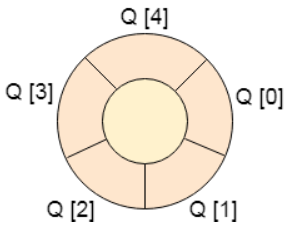
循环队列1 简介概念 在循环队列中,最后一个索引紧跟在第一个索引之后。 当front = -1和rear = max-1时,循环队列将满。循环队列的实现类似于线性队列的实现。只有在插入和删除的情况下实现的逻辑部分与线性队列中的逻辑部分不同。 时间复杂度 操作 Front O(1) Rear O(1) enQueue() O(1) deQueue() O(1) 2 循环队列的操作基本操作 创建 遍历、搜索、查找(显示第一个元素) 插入 删除 3 循环队列的实现数组实现123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106#include<stdio.h> ...
5 散列表
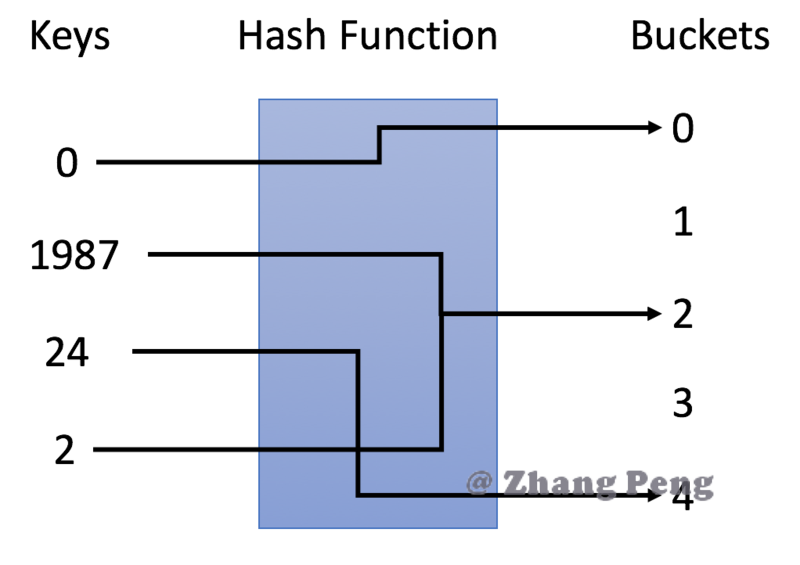
哈希表 包含集合和映射。即unordered_set和unordreed_map两种数据结构的实现方式。 参考文献 https://www.cnblogs.com/gongcheng-/p/10894205.html#_label1_0 1 哈希表简介哈希表的概念 哈希表是一种使用哈希函数组织数据,以支持快速插入和搜索的数据结构。 通过选择合适的哈希函数,哈希表可以在插入和搜索方面实现出色的性能。 哈希表的分类 有两种不同类型的哈希表:哈希集合和哈希映射。 哈希集合是集合set数据结构的实现之一,用于存储非重复值。 哈希映射是映射map 数据结构的实现之一,用于存储(key, value)键值对。 2 哈希表的原理原理说明 哈希表的关键思想是使用哈希函数将键映射到存储桶。更确切地说, 当我们插入一个新的键时,哈希函数将决定该键应该分配到哪个桶中,并将该键存储在相应的桶中; 当我们想要搜索一个键时,哈希表将使用相同的哈希函数来查找对应的桶,并只在特定的桶中进行搜索。 哈希函数 在示例中,我们使用 y = x % 5 作为哈希函数。让我们使用这个例...

4.2 优先队列
优先队列1 优先队列简介3 优先队列的操作基本操作 创建 遍历、搜索、查找(显示第一个元素) 插入 删除 3 优先队列的实现数组实现循环链表实现C++模板123#include<queue>queue<int> que;




