
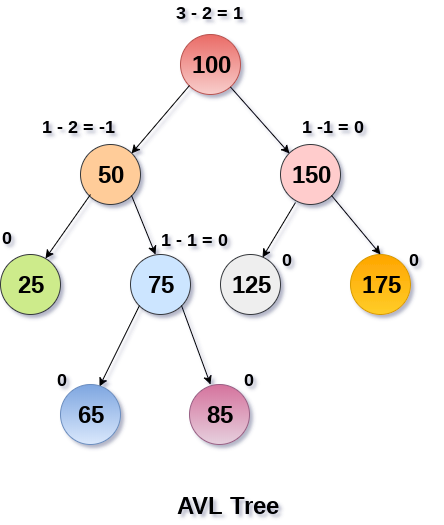
6.3 平衡二叉树
平衡二叉树 树>二叉树>二叉搜索树>二叉平衡树 参考文献 AVL 1 简介概念 满足二叉搜索树的定义 所有结点的平衡因子的绝对值都不超过1,即平衡因子只能是1,0,-1三个值。 如果任何节点的平衡因子为1,则意味着左子树比右子树高一级。 如果任何节点的平衡因子为0,则意味着左子树和右子树包含相等的高度。 如果任何节点的平衡因子是-1,则意味着左子树比右子树低一级。 1平衡系数=左子树的高度 - 右子树的高度 复杂性 算法 平均情况 最坏情况 空间 o(n) o(n) 搜索 o(log n) o(log n) 插入 o(log n) o(log n) 删除 o(log n) o(log n) 优势 AVL树能防止二叉树偏斜,控制二叉搜索树的高度。高度为h的二叉搜索树中的所有操作所花费的时间是O(h)。 如果普通二叉搜索树变得偏斜(即最坏的情况),它可以扩展到O(n)。 通过将该高度限制为log n,AVL树将每个操作的上限强加为O(log n),其中n是节点的数量 2 操作基本操作 创建 遍历(同上) 插入 删除 ...
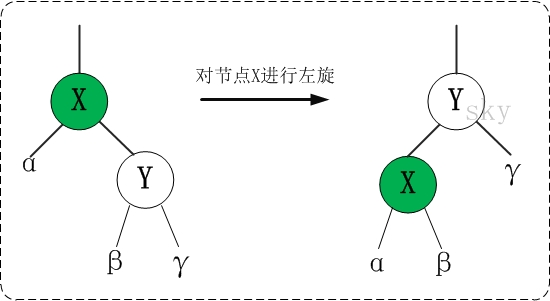
6.4 红黑树
红黑树 树>二叉树>二叉搜索树>平衡二叉搜索树>红黑树(自平衡二叉搜索树) 参考文献 红黑树 1 简介定义 满足二叉搜索树的定义。 每个节点或者是黑色,或者是红色。 根节点是黑色。每个叶子节点(NIL)是黑色。(这里叶子节点,是指为空NULL的叶子节点!) 如果一个节点是红色的,则它的子节点必须是黑色的。 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。 优势 主要是用它来存储有序的数据,它的时间复杂度是O(lgn),效率非常之高。 时间复杂度 红黑树的时间复杂度为: O(lgn) 2 操作 太过复杂,日后处理,根据参考文献。 基础操作 创建 遍历(同上) 插入 删除 旋转和着色 插入 第一步: 将红黑树当作一颗二叉查找树,将节点插入。 红黑树本身就是一颗二叉查找树,将节点插入后,该树仍然是一颗二叉查找树。也就意味着,树的键值仍然是有序的。此外,无论是左旋还是右旋,若旋转之前这棵树是二叉查找树,旋转之后它一定还是二叉查找树。这也就意味着,任何的旋转和重新着色操作,都不会改变它仍然是一颗二叉查找树的事实。 好吧?那接下来,...
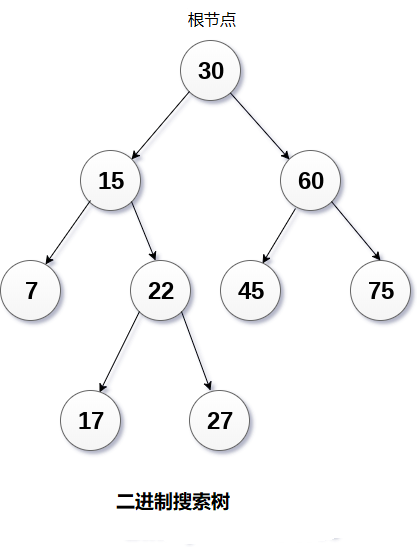
6.2 二叉搜索树
二叉搜索树 树>二叉树>二叉搜索树 1 简介概念 二叉搜索树是二叉树,其节点按特定顺序排列。也称为称为有序二叉树。 左子树中所有节点的值小于根的值。 右子树中所有节点的值大于或等于根的值。 此规则将递归地应用于根的所有左子树和右子树 优点 在搜索过程中,它会在每一步删除半个子树。 在二叉搜索树中搜索元素需要o(log2n)时间。 在最坏的情况下,搜索元素所花费的时间是0(n)。 与数组和链表中的操作相比,它还加快了插入和删除操作。 2 基本操作基本操作 创建 遍历(同上) 插入 删除 遍历 二叉搜索树的前序遍历。 二叉搜索书的中序遍历。中序的输出结果其实就是二叉搜索树排序后的结果。 二叉搜索树的后续遍历。 插入 使用下列元素创建二叉树的过程 143, 10, 79, 90, 12, 54, 11, 9, 50 删除3 二叉搜索树实现1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859...

6.6 B+树
B+树 参考文献 B树B+树 1 简介概念 像是在建立额外的索引 有m个子树的中间节点包含有m个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引; 所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (而B 树的叶子节点并没有包括全部需要查找的信息); 所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息); 优点 B+树的磁盘读写代价更低 B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了; B+树查询效率更加稳定 由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当; B+树便于范围查...
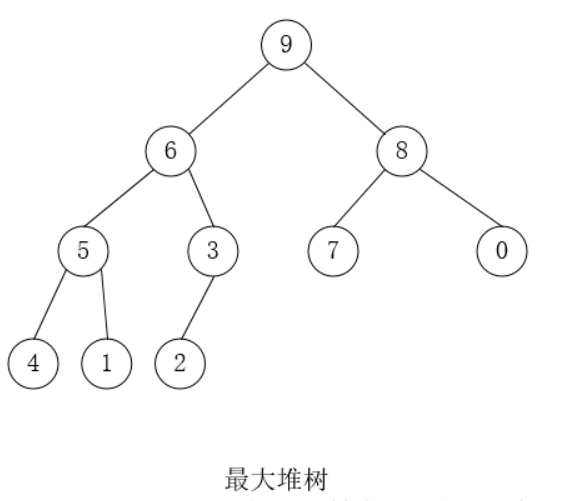
6.8 堆树
堆 二叉搜索树、多路搜索树都是左小右大。堆树是上下大小不一样。 二叉搜索树是从根节点向叶子节点构造。进行插入。堆树是从叶子节点,向根节点进行构造。 参考文献 堆,但是有很严重的错误 1 简介 堆是一颗完全二叉树; 堆中的某个结点的值总是大于等于(最大堆)或小于等于(最小堆)其孩子结点的值。 堆中每个结点的子树都是堆树。 因为堆的第三条性质,堆的每一个子树,都是一个堆树。如果从叶节点开始进行一次向上调整。虽然能够保证最大值上浮到根节点。但是却无法保证它是一个堆树。因为进行一次向上调整。根节点的子树也许不是堆树。 使用数组表示的堆树 应用 堆结构的一个常见应用是建立优先队列(Priority Queue)。 普通树占用的内存空间比它们存储的数据要多。你必须为节点对象以及左/右子节点指针分配内存。堆仅仅使用一个数组来存储数组,且不使用指针。 2 操作基本操作 上浮 下沉 取顶 创建:把一个乱序的数组变成堆结构的数组,时间复杂度为 $O(n)$ 插入:把一个数值放进已经是堆结构的数组中,并保持堆结构,时间复杂度为 $O(log N)$ 删除:从最大...

17.临时对象
临时对象定义 C++直接调用构造函数。会创建临时对象。 临时对象没有对象名,它的生命周期只有一条语句。 如果直接调用构造函数,赋值给一个具体的名字,则会使用复制初始化。则不是临时对象。 使用 如果做为函数参数使用。调用的是复制噶偶早函数。 12vector<vector<int> > vec;vec.push_back(vector<int>(5));//直接调用构造函数,会创建临时对象。 如果作为返回值使用。调用的是复制构造函数。 123vector<int> hello(){ return vector<int>();}
0 数据结构基础
数据结构基础 参考文献 易佰教程 1 简介数据结构的组成 数据结构主要包括两部分。 数据的结构。包括存储结构和逻辑结构。存储结构决定在其在计算机内存中的表现形式和具有的特点。逻辑结构决定了“数据”内部之间的关联结构。 数据的规则。基于数据的存储结构和逻辑结构。衍生出数据的一系列基本操作。包括创建、遍历、插入、删除等,每一类数据结构都有其相应的基础操作。 本目录主要讲解了。数据的结构和数据的规则。以及这两个东西的实现方法。不包括在这些数据的和数据的规则之上的更顶层的算法。如基于前序遍历(数据的规则)的什么什么算法(上层的算法)。 数据结构预算法 基本术语数据结构是任何程序或软件的构建块(基础块)。为程序选择适当的数据结构对于程序员来说是最困难的任务。就数据结构而言,使用以下术语 - 数据:数据可以定义为基本值或值集合,例如,学生的姓名和ID,成绩等就是学生的数据。 组项:具有从属数据项的数据项称为组项,例如,学生的姓名由名字和姓氏组成。 记录:记录可以定义为各种数据项的集合,例如,如果以学生实体为例,那么学生的名称,地址,课程和标记可以组合在一起形成学生的记录。...
1 数组
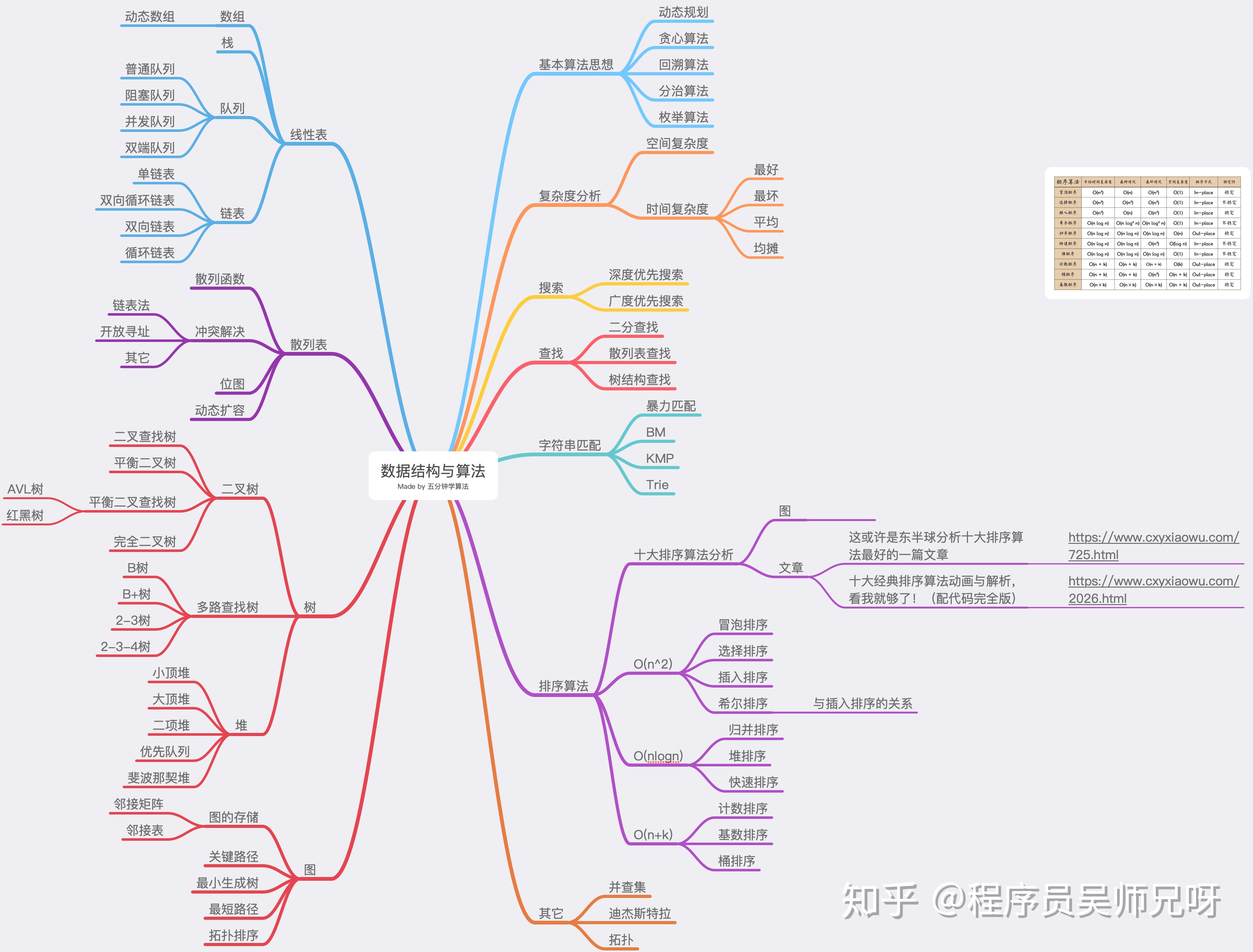
数组1 数组的简介定义 数组是存储在连续内存位置的相同类型数据项的集合,是最简单的线性数据结构。 数组的每个数据元素都可以使用下表索引运算符,进行随机访问。 数组可以有一个或多个维度。 每个元素具有相同的数据类型并且具有相同的大小,即int = 4个字节。 123int arr[10];char arr[10]; float arr[5]; 优点 数组为同一类型的变量组提供单一名称,因此很容易记住数组中所有元素的名称。 遍历数组是一个非常简单的过程,只需要递增数组的基址,就可以逐个访问每个元素。 可以使用索引直接访问数组中的任何元素。 时间复杂性 算法 平均情况 最坏情况 访问 O(1) O(1) 搜索 O(n) O(n) 插入 O(n) O(n) 删除 O(n) O(n) 空间复杂性 在数组中,最坏情况下的空间复杂度是O(n)。 2 数组的类型一维数组 一维(或单维)数组是一种线性数组,其中元素的访问是以行或列索引的单一下标表示。 C++ 将高维维数组存储为一维数组。因此,如果我们将 A 定义为也包含 M * N 个元素的二维数...

2 链表
链表1 简介链表概念 链表是一种随机存储在内存中的节点对象集合。 节点包含两个字段,即存储在该地址的数据和包含下一个节点地址的指针。 链表的最后一个节点包含指向null的指针。 链表特点 链表不需要连续存在于存储器中。节点可以是存储器中的任何位置并链接在一起以形成链表。这实现了空间的优化利用。 链表大小仅限于内存大小,不需要提前声明。 空节点不能出现在链表中。 在单链表中存储基元类型或对象的值。 链表与数组的对比 数组有以下限制: 在程序中使用数组之前,必须事先知道数组的大小。 增加数组的大小是一个耗时的过程。在运行时几乎不可能扩展数组的大小。 数组中的所有元素都需要连续存储在内存中。在数组中插入任何元素都需要移动元素之前所有的数据。 链表是可以克服数组所有限制的数据结构。 链表是非常有用的,因为, 它动态分配内存。链表的所有节点都是非连续存储在存储器中,并使用指针链接在一起。 大小调整不再是问题,因为不需要在声明时定义大小。链表根据程序的需求增长,并且仅限于可用的内存空间。 2 链表的类型分类 单链表 双链表 循环单链表 循环双链表
3 栈
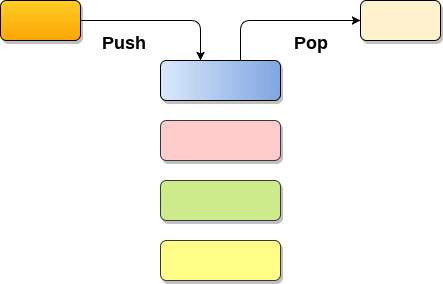
堆栈1 简介概念 堆栈(stack)又称为栈,是计算机科学中一种特殊的串列形式的抽象数据类型, 堆栈(Stack)是一个有序列表,它只能在顶端执行插入和删除。 堆栈(Stack)是一个递归数据结构,具有指向其顶部元素的指针。 堆栈为后进先出(LIFO)列表,即首先插入堆栈的元素将最后从堆栈中删除. 应用 深度优先搜索与回溯 递归 表达式评估和转换 解析 浏览器 编辑器 树遍历 特点 先入后出,后入先出。 除头尾节点之外,每个元素有一个前驱,一个后继。 2 栈的操作基础操作 推入 push 将数据放入堆栈的顶端(数组形式或串列形式),堆栈顶端 top 指针加一。 弹出 pop 将顶端数据数据输出(回传),堆栈顶端数据减一。 查看 top 查看栈顶的元素而不删除它们。 以后有时间来实现这些数据结构 3 栈的实现数组实现12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656...




