

01.String 是如何实现的?它有哪些重要的方法?
String 是如何实现的?它有哪些重要的方法?几乎所有的 Java 面试都是以 String 开始的,如果第一个问题没有回答好,则会给面试官留下非常不好的第一印象,而糟糕的第一印象则会直接影响到自己的面试结果,就好像刚破壳的小鹅一样,会把第一眼看到的动物当成自己的母亲,即使它第一眼看到的是一只小狗或小猫,也会默认跟随其后,心理学把这种现象叫做印刻效应。印刻效应不仅存在于低等动物之中,同样也适用于人类,所以对于 String 的知识,我们必须深入的掌握才能为自己赢得更多的筹码。 本课时的问题是:String 是如何实现的?它有哪些重要的方法? 典型回答以主流的 JDK 版本 1.8 来说,String 内部实际存储结构为 char 数组,源码如下: 1234567public final class String implements java.io.Serializable,Comparable<String>,CharSequence{ //用于存储字符串的值 private final charvalue[]; //缓存字符串的 ha...
02.HashMap 底层实现原理是什么?JDK8 做了哪些优化?
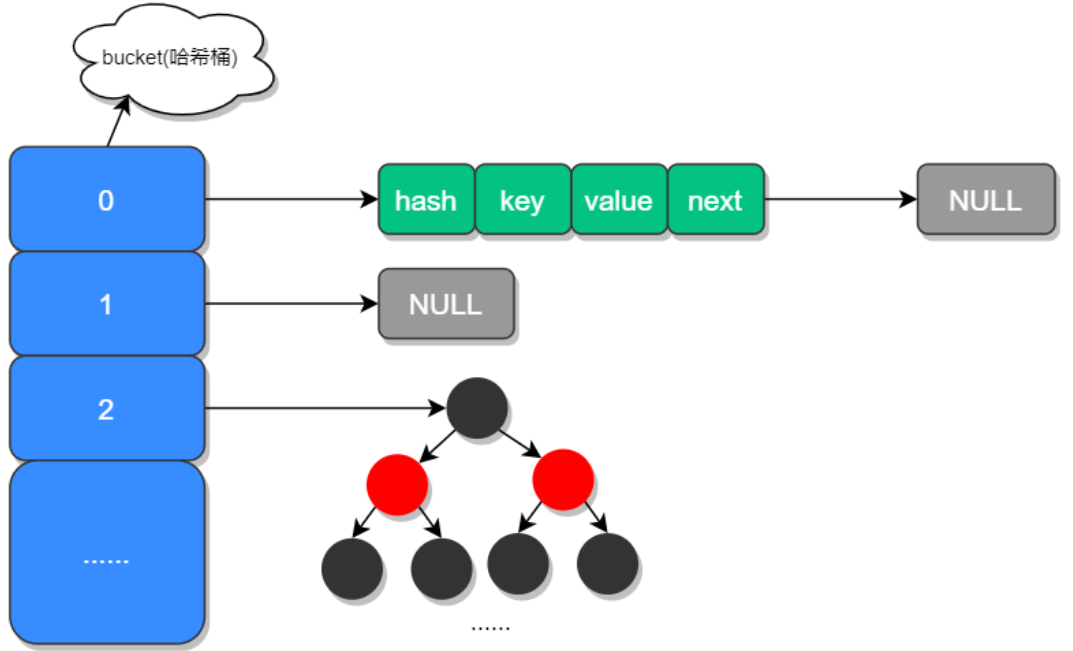
HashMap 底层实现原理是什么?JDK8 做了哪些优化?HashMap 是使用频率最高的类型之一,同时也是面试经常被问到的问题之一,这是因为 HashMap 的知识点有很多,同时它又属于 Java 基础知识的一部分,因此在面试中经常被问到。 本课时的面试题是,HashMap 底层是如何实现的?在 JDK 1.8 中它都做了哪些优化? 典型回答在JDK1.7中HashMap是以数组加链表的形式组成的,JDK1.8之后新增了红黑树的组成结构,当链表大于8时,链表结构会转换成红黑树结构,它的组成结构如下图所示: 数组中的元素我们称之为哈希桶,它的定义如下: 123456789101112131415161718192021222324252627282930313233343536373839static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V&...
03.线程的状态有哪些?它是如何工作的?
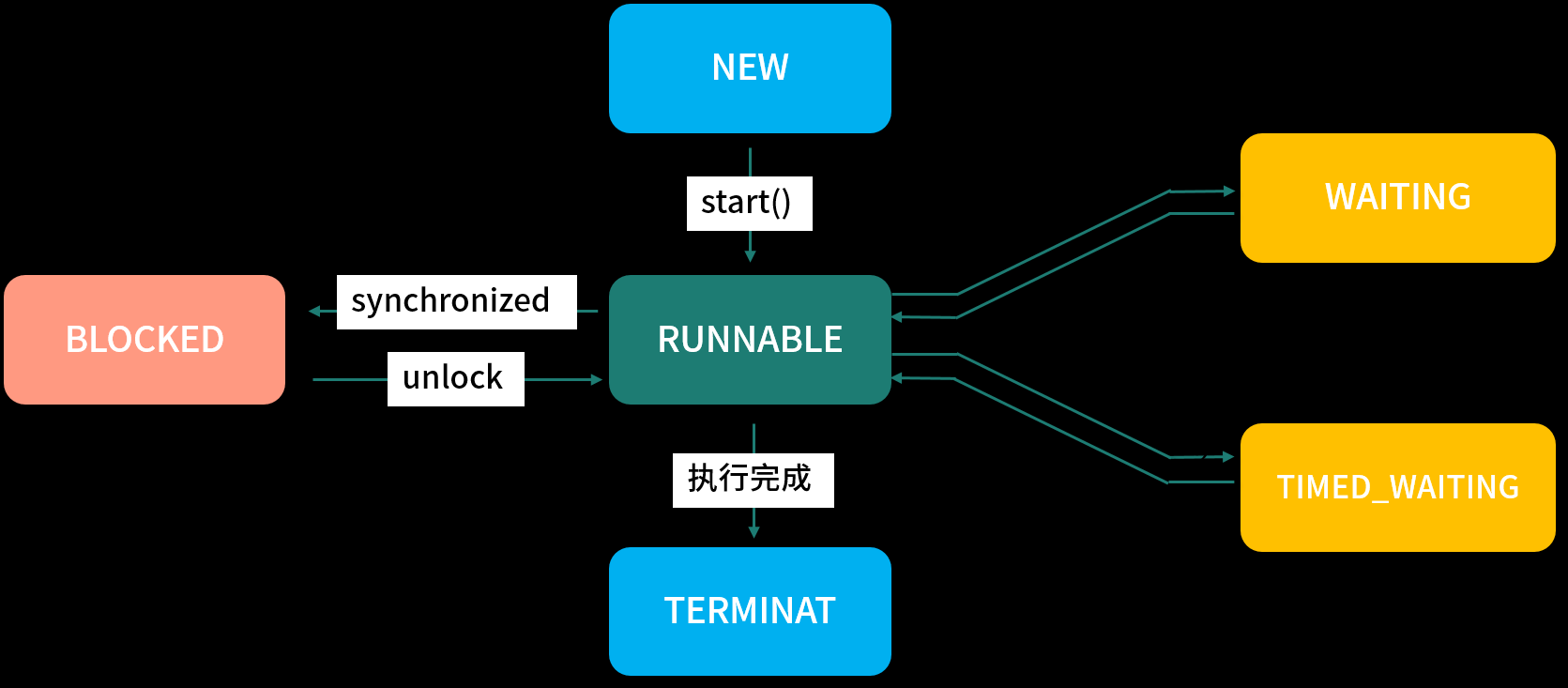
线程的状态有哪些?它是如何工作的?线程(Thread)是并发编程的基础,也是程序执行的最小单元,它依托进程而存在。一个进程中可以包含多个线程,多线程可以共享一块内存空间和一组系统资源,因此线程之间的切换更加节省资源、更加轻量化,也因此被称为轻量级的进程。 当然,线程也是面试中常被问到的一个知识点,是程序员必备的基础技能,使用它可以有效地提高程序的整体运行速度。 本课时的面试问题是,线程的状态有哪些?它是如何工作的? 典型回答线程的状态在 JDK 1.5 之后以枚举的方式被定义在 Thread 的源码中,它总共包含以下 6 个状态: NEW,新建状态,线程被创建出来,但尚未启动时的状态; RUNNABLE,就绪状态,表示可以运行的线程状态,它可能正在运行,或者是排队等待CPU分配给它资源; BLOCKED,阻塞等待锁的线程状态,表示处于阻塞状态的线程正在等待监视器锁,比如等待执行synchronized代码块或者使用synchronized标记的方法; WAITING,等待状态,一个处于等待状态的线程正在等待另一个线程执行某个特定的动作,比如,一个线程调用了Object.wait...
04.详解 ThreadPoolExecutor 的参数含义及源码执行流程?
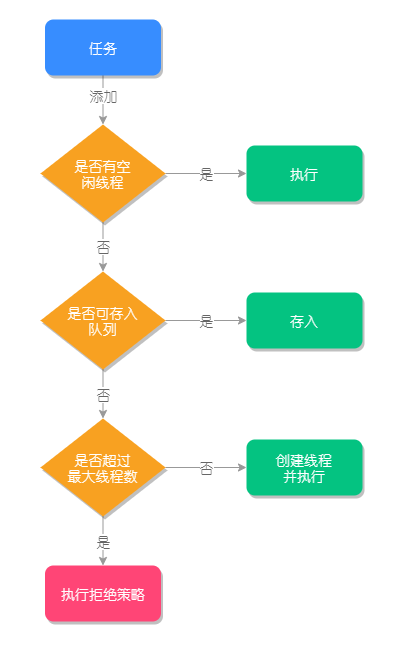
详解 ThreadPoolExecutor 的参数含义及源码执行流程?线程池是为了避免线程频繁的创建和销毁带来的性能消耗,而建立的一种池化技术,它是把已创建的线程放入“池”中,当有任务来临时就可以重用已有的线程,无需等待创建的过程,这样就可以有效提高程序的响应速度。但如果要说线程池的话一定离不开**ThreadPoolExecutor,在阿里巴巴的《Java开发手册》中是这样规定线程池的:线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor**的方式,这样的处理方式让写的读者更加明确线程池的运行规则,规避资源耗尽的风险。 说明:Executors 返回的线程池对象的弊端如下: 1)FixedThreadPool 和 SingleThreadPool:允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM(Out Of Memory) 2)CachedThreadPool 和 ScheduledThreadPool:允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 ...
06.谈谈你对锁的理解?如何手动模拟一个死锁?
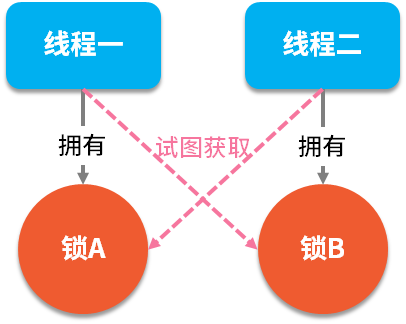
谈谈你对锁的理解?如何手动模拟一个死锁?在并发编程中有两个重要的概念:线程和锁,多线程是一把双刃剑,它在提高程序性能的同时,也带来了编码的复杂性,对开发者的要求也提高了一个档次。而锁的出现就是为了保障多线程在同时操作一组资源时的数据一致性,当我们给资源加上锁之后,只有拥有此锁的线程才能操作此资源,而其他线程只能排队等待使用此锁。当然,在所有的面试中也都少不了关于“锁”方面的相关问题。 典型回答死锁是指两个线程同时占用两个资源,又在彼此等待对方释放锁资源,如下图所示: 死锁的代码演示如下: 12345678910111213141516171819202122232425262728293031323334353637383940414243import java.util.concurrent.TimeUnit;public class LockExample { public static void main(String[] args) { deadLock(); // 死锁 }/** * 死锁 */private s...
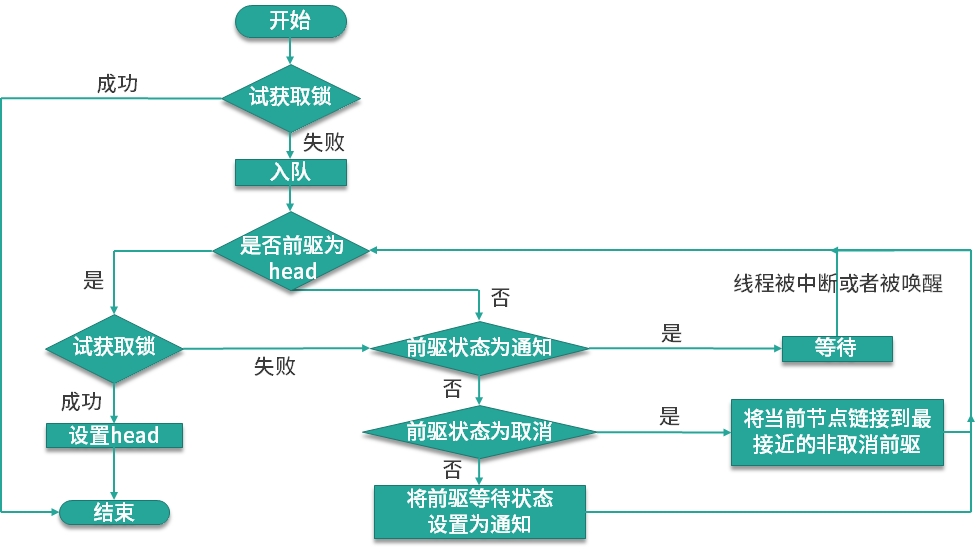
05.synchronized和ReentrantLock
synchronized 和 ReentrantLock 的实现原理是什么?它们有什么区别?在 JDK 1.5 之前共享对象的协调机制只有 synchronized 和 volatile,在 JDK 1.5 中增加了新的机制 ReentrantLock,该机制的诞生并不是为了替代 synchronized,而是在 synchronized 不适用的情况下,提供一种可以选择的高级功能。 典型回答synchronized 属于独占式悲观锁,是通过 JVM 隐式实现的,synchronized 只允许同一时刻只有一个线程操作资源。 在 Java 中每个对象都隐式包含一个 monitor(监视器)对象,加锁的过程其实就是竞争 monitor 的过程,当线程进入字节码 monitorenter 指令之后,线程将持有 monitor 对象,执行 monitorexit 时释放 monitor 对象,当其他线程没有拿到 monitor 对象时,则需要阻塞等待获取该对象。 ReentrantLock 是 Lock 的默认实现方式之一,它是基于 AQS(Abstract Queued Sync...

07.深克隆和浅克隆有什么区别?它的实现方式有哪些?
深克隆和浅克隆有什么区别?它的实现方式有哪些?使用克隆可以为我们快速地构建出一个已有对象的副本,它属于 Java 基础的一部分,也是面试中常被问到的知识点之一。 我们本课时的面试题是,什么是浅克隆和深克隆?如何实现克隆? 典型回答浅克隆(Shadow Clone)是把原型对象中成员变量为值类型的属性都复制给克隆对象,把原型对象中成员变量为引用类型的引用地址也复制给克隆对象,也就是原型对象中如果有成员变量为引用对象,则此引用对象的地址是共享给原型对象和克隆对象的。 简单来说就是浅克隆只会复制原型对象,但不会复制它所引用的对象,如下图所示: 深克隆(Deep Clone)是将原型对象中的所有类型,无论是值类型还是引用类型,都复制一份给克隆对象,也就是说深克隆会把原型对象和原型对象所引用的对象,都复制一份给克隆对象,如下图所示: 在 Java 语言中要实现克隆则需要实现 Cloneable 接口,并重写 Object 类中的 clone() 方法,实现代码如下: 123456789101112131415161718192021222324252627282930313233343...

08.动态代理是如何实现的?JDK Proxy 和 CGLib 有什么区别?
动态代理是如何实现的?JDK Proxy 和 CGLib 有什么区别?90% 的程序员直接或者间接的使用过动态代理,无论是日志框架或 Spring 框架,它们都包含了动态代理的实现代码。动态代理是程序在运行期间动态构建代理对象和动态调用代理方法的一种机制。 我们本课时的面试题是,如何实现动态代理?JDK Proxy 和 CGLib 有什么区别? 典型回答动态代理的常用实现方式是反射。反射机制是指程序在运行期间可以访问、检测和修改其本身状态或行为的一种能力,使用反射我们可以调用任意一个类对象,以及类对象中包含的属性及方法。 但动态代理不止有反射一种实现方式,例如,动态代理可以通过 CGLib 来实现,而 CGLib 是基于 ASM(一个 Java 字节码操作框架)而非反射实现的。简单来说,动态代理是一种行为方式,而反射或 ASM 只是它的一种实现手段而已。 JDK Proxy 和 CGLib 的区别主要体现在以下几个方面: JDK Proxy 是 Java 语言自带的功能,无需通过加载第三方类实现; Java 对 JDK Proxy 提供了稳定的支持,并且会持续的升级和更新 JD...

10.如何手写一个消息队列和延迟消息队列?
如何手写一个消息队列和延迟消息队列?第一次听到“消息队列”这个词时,不知你是不是和我反应一样,感觉很高阶很厉害的样子,其实当我们了解了消息队列之后,发现它与普通的技术类似,当我们熟悉之后,也能很快地上手并使用。 我们本课时的面试题是,消息队列的使用场景有哪些?如何手动实现一个消息队列和延迟消息队列? 典型回答消息队列的使用场景有很多,最常见的使用场景有以下几个。 1.商品秒杀比如,我们在做秒杀活动时,会发生短时间内出现爆发式的用户请求,如果不采取相关的措施,会导致服务器忙不过来,响应超时的问题,轻则会导致服务假死,重则会让服务器直接宕机,给用户带来的体验也非常不好。如果这个时候加上了消息队列,服务器接收到用户的所有请求后,先把这些请求全部写入到消息队列中再排队处理,这样就不会导致同时处理多个请求的情况;如果消息队列长度超过可以承载的最大数量,那么我们可以抛弃当前用户的请求,通知前台用户“页面出错啦,请重新刷新”等提示,这样就会有更好的交互体验。 2.系统解耦使用了消息队列之后,我们可以把系统的业务功能模块化,实现系统的解耦。例如,在没有使用消息队列之前,当前台用户完善了个人信息之...

09.如何实现本地缓存和分布式缓存?
如何实现本地缓存和分布式缓存?缓存(Cache) 是指将程序或系统中常用的数据对象存储在像内存这样特定的介质中,以避免在每次程序调用时,重新创建或组织数据所带来的性能损耗,从而提高了系统的整体运行速度。 以目前的系统架构来说,用户的请求一般会先经过缓存系统,如果缓存中没有相关的数据,就会在其他系统中查询到相应的数据并保存在缓存中,最后返回给调用方。 缓存既然如此重要,那本课时我们就来重点看一下,应该如何实现本地缓存和分布式缓存? 典型回答本地缓存是指程序级别的缓存组件,它的特点是本地缓存和应用程序会运行在同一个进程中,所以本地缓存的操作会非常快,因为在同一个进程内也意味着不会有网络上的延迟和开销。 本地缓存适用于单节点非集群的应用场景,它的优点是快,缺点是多程序无法共享缓存,比如分布式用户 Session 会话信息保存,由于每次用户访问的服务器可能是不同的,如果不能共享缓存,那么就意味着每次的请求操作都有可能被系统阻止,因为会话信息只保存在某一个服务器上,当请求没有被转发到这台存储了用户信息的服务器时,就会被认为是非登录的违规操作。 除此之外,无法共享缓存可能会造成系统资源的浪费...




