
01机器学习(ML)策略(1)
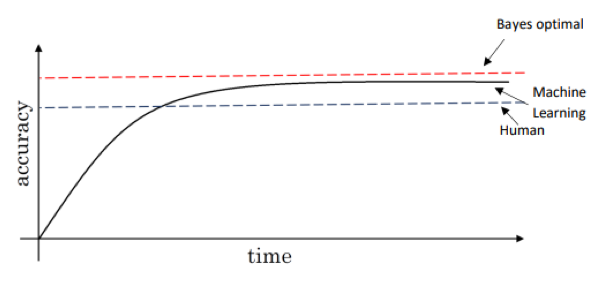
机器学习(ML)策略(1) 对于一个已经被构建好且产生初步结果的机器学习系统,为了能使结果更令人满意,往往还要进行大量的改进。鉴于之前的课程介绍了多种改进的方法,例如收集更多数据、调试超参数、调整神经网络的大小或结构、采用不同的优化算法、进行正则化等等,我们有可能浪费大量时间在一条错误的改进路线上。想要找准改进的方向,使一个机器学习系统更快更有效地工作,就需要学习一些在构建机器学习系统时常用到的策略。 正交化正交化定义和例子 正交化(Orthogonalization) 的核心在于每次调整只会影响模型某一方面的性能,而对其他功能没有影响。这种方法有助于更快更有效地进行机器学习模型的调试和优化。 电视旋钮的例子,可以用来调整宽度、高度、梯度、位置的旋钮,互相独立,互不影响。 汽车行驶的例子,汽车的方向和汽车的速度分别通过方向盘与油门刹车控制,互不影响。 在机器学习(监督学习)系统中,可以划分四个“功能”: 建立的模型在训练集上表现良好; 建立的模型在验证集上表现良好; 建立的模型在测试集上表现良好; 建立的模型在实际应用中表现良好。 对于不同的目的,采取不同的方法: 对...
02机器学习(ML)策略(2)
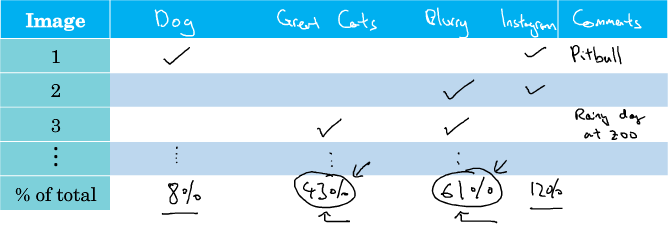
机器学习(ML)策略(2)错误分析 通过人工检查机器学习模型得出的结果中出现的一些错误,有助于深入了解下一步要进行的工作。这个过程被称作错误分析(Error Analysis)。 例如,你可能会发现一个猫图片识别器错误地将一些看上去像猫的狗误识别为猫。这时,立即盲目地去研究一个能够精确识别出狗的算法不一定是最好的选择,因为我们不知道这样做会对提高分类器的准确率有多大的帮助。 这时,我们可以从分类错误的样本中统计出狗的样本数量。根据狗样本所占的比重来判断这一问题的重要性。假如狗类样本所占比重仅为 5%,那么即使花费几个月的时间来提升模型对狗的识别率,改进后的模型错误率并没有显著改善;而如果错误样本中狗类所占比重为 50%,那么改进后的模型性能会有较大的提升。因此,花费更多的时间去研究能够精确识别出狗的算法是值得的。 这种人工检查看似简单而愚笨,但却是十分必要的,因为这项工作能够有效避免花费大量的时间与精力去做一些对提高模型性能收效甚微的工作,让我们专注于解决影响模型准确率的主要问题。 在对输出结果中分类错误的样本进行人工分析时,可以建立一个表格来记录每一个分类错误的具体信息...











