
01深度学习的实用层面
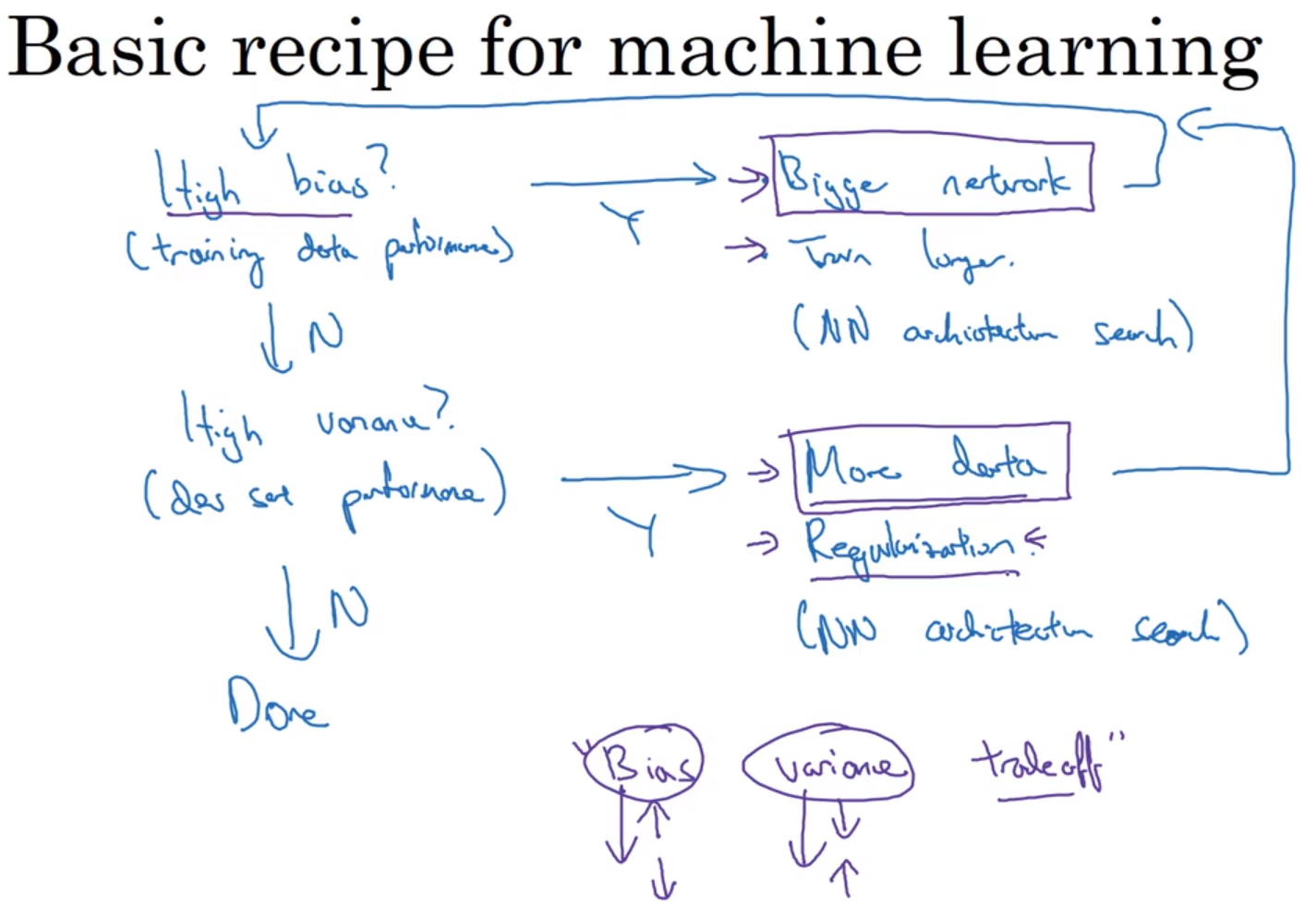
# 深度学习的实用层面 > * [笔记模板](https://github.com/bighuang624/Andrew-Ng-Deep-Learning-notes) > * 相关的笔记都可以在github上先找到相关的笔记然后再修改,方便。 ## 数据划分:训练 / 验证 / 测试集 * 应用深度学习是一个典型的迭代过程。 * `->idea -> code -> employment->` * 对于一个需要解决的问题的样本数据,在建立模型的过程中,数据会被划分为以下几个部分: * 训练集(train set):用训练集对算法或模型进行**训练**过程; * 验证集(development set):利用验证集(又称为简单交叉验证集,hold-out cross validation set)进行**交叉验证**,**选择出最好的模型**; * 测试集(test set):最后利用测试集对模型进行测试,**获取模型运行的无偏估计**(对学习方法进行评估)。 * 在**小数据量**的时代,如 100、1000、10000 的数据量大小,可以将数据集...

readme
这里主要以各种算法的理论知识为主进行说明。 从算法的角度,进行说明。(算法角度的理论总结) 算法相关的项目的实现。(机器学习实战)
02深度卷积网络:实例探究
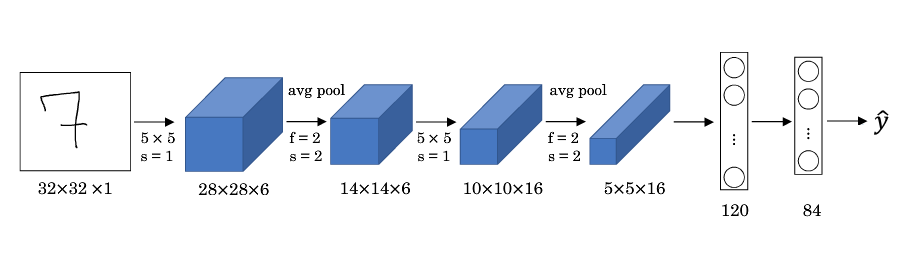
卷积神经网络:实例探究1 卷积网络说明 讲到的经典 CNN 模型包括: LeNet-5 AlexNet VGG ResNet(Residual Network,残差网络) Inception Neural Network。 2 经典卷积网络LeNet-5 特点: LeNet-5 针对灰度图像而训练,因此输入图片的通道数为 1。 该模型总共包含了约 6 万个参数,远少于标准神经网络所需。 典型的 LeNet-5 结构包含卷积层(CONV layer),池化层(POOL layer)和全连接层(FC layer),排列顺序一般为 CONV layer->POOL layer->CONV layer->POOL layer->FC layer->FC layer->OUTPUT layer。一个或多个卷积层后面跟着一个池化层的模式至今仍十分常用。 当 LeNet-5模型被提出时,其池化层使用的是平均池化,而且各层激活函数一般选用 Sigmoid 和 tanh。现在,我们可以根据需要,做出改进,使用最大池化并选用 ReLU 作为激活函数。 ...

03目标检测
目标检测 目标检测是计算机视觉领域中一个新兴的应用方向,其任务是对输入图像进行分类的同时,检测图像中是否包含某些目标,并对他们准确定位并标识。 1 目标定位 定位分类问题不仅要求判断出图片中物体的种类,还要在图片中标记出它的具体位置,用**边框(Bounding Box,或者称包围盒)**把物体圈起来。一般来说,定位分类问题通常只有一个较大的对象位于图片中间位置;而在目标检测问题中,图片可以含有多个对象,甚至单张图片中会有多个不同分类的对象。 为了定位图片中汽车的位置,可以让神经网络多输出 4 个数字,标记为 $b_x$、$b_y$、$b_h$、$b_w$。将图片左上角标记为 (0, 0),右下角标记为 (1, 1),则有: 红色方框的中心点:($b_x$,$b_y$) 边界框的高度:$b_h$ 边界框的宽度:$b_w$ 因此,训练集不仅包含对象分类标签,还包含表示边界框的四个数字。定义目标标签 Y 如下: $$\left[\begin{matrix}P_c\\ b_x\\ b_y\\ b_h\\ b_w\\ c_1\\ c_2\\ c_3\end{matrix}\...
循环序列模型
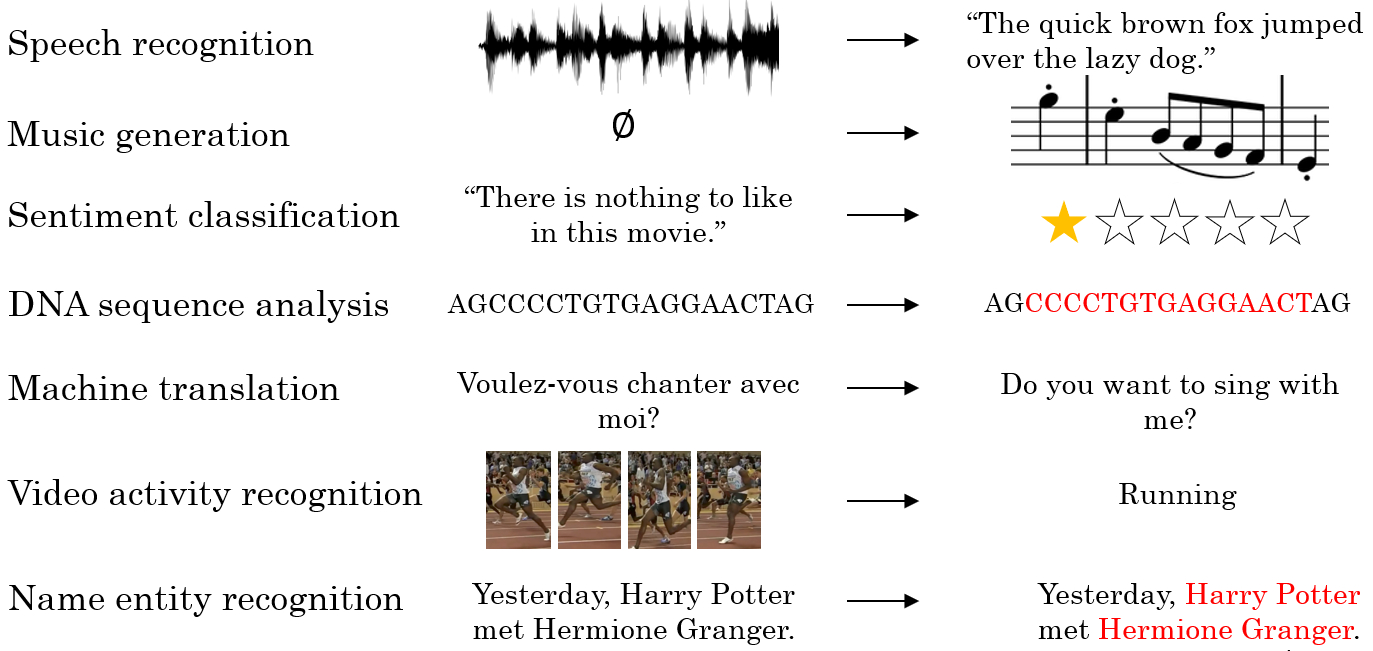
循环序列模型1 循环神经网络 自然语言和音频都是前后相互关联的数据,对于这些序列数据需要使用**循环神经网络(Recurrent Neural Network,RNN)**来进行处理。 使用 RNN 实现的应用包括下图中所示: 2 数学符号 对于一个序列数据 $x$,用符号 $x^{⟨t⟩}$来表示这个数据中的第 $t$个元素,用 $y^{⟨t⟩}$来表示第 $t$个标签,用 $T_x$ 和 $T_y$来表示输入和输出的长度。对于一段音频,元素可能是其中的几帧;对于一句话,元素可能是一到多个单词。 第 $i$ 个序列数据的第 $t$ 个元素用符号 $x^{(i)⟨t⟩}$,第 $t$ 个标签即为 $y^{(i)⟨t⟩}$。对应即有 $T^{(i)}_x$ 和 $T^{(i)}_y$。 one-hot 想要表示一个词语,需要先建立一个词汇表(Vocabulary),或者叫字典(Dictionary)。将需要表示的所有词语变为一个列向量,可以根据字母顺序排列,然后根据单词在向量中的位置,用 one-hot 向量(one-hot vector) 来表示该单词的标签:将每个...
04特殊应用:人脸识别和神经风格迁移
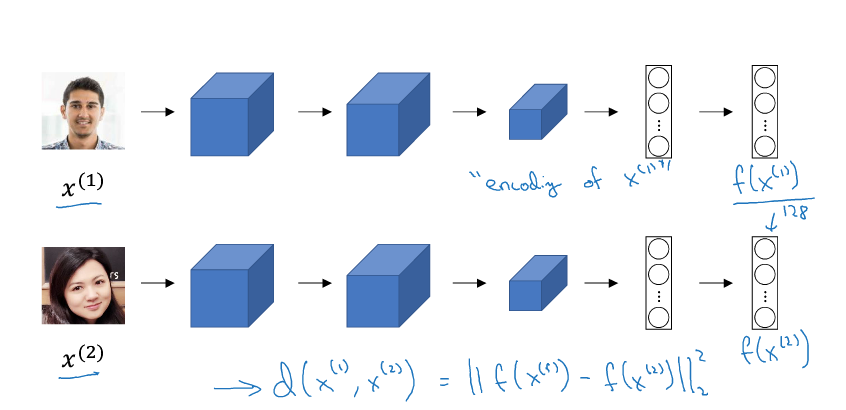
特殊应用:人脸识别和神经风格转换 1 人脸识别定义 人脸验证(Face Verification) 和 人脸识别(Face Recognition) 的区别: 人脸验证:一般指一个一对一问题,只需要验证输入的人脸图像是否与某个已知的身份信息对应; 人脸识别:一个更为复杂的一对多问题,需要验证输入的人脸图像是否与多个已知身份信息中的某一个匹配。 一般来说,由于需要匹配的身份信息更多导致错误率增加,人脸识别比人脸验证更难一些。 2 One-Shot 学习 人脸识别所面临的一个挑战是要求系统只采集某人的一个面部样本,就能快速准确地识别出这个人,即只用一个训练样本来获得准确的预测结果。这被称为One-Shot 学习。 有一种方法是假设数据库中存有 N 个人的身份信息,对于每张输入图像,用 Softmax 输出 N+1 种标签,分别对应每个人以及都不是。然而这种方法的实际效果很差,因为过小的训练集不足以训练出一个稳健的神经网络;并且如果有新的身份信息入库,需要重新训练神经网络,不够灵活。 因此,我们通过学习一个 Similarity 函数来实现 One-Shot 学习过程。S...
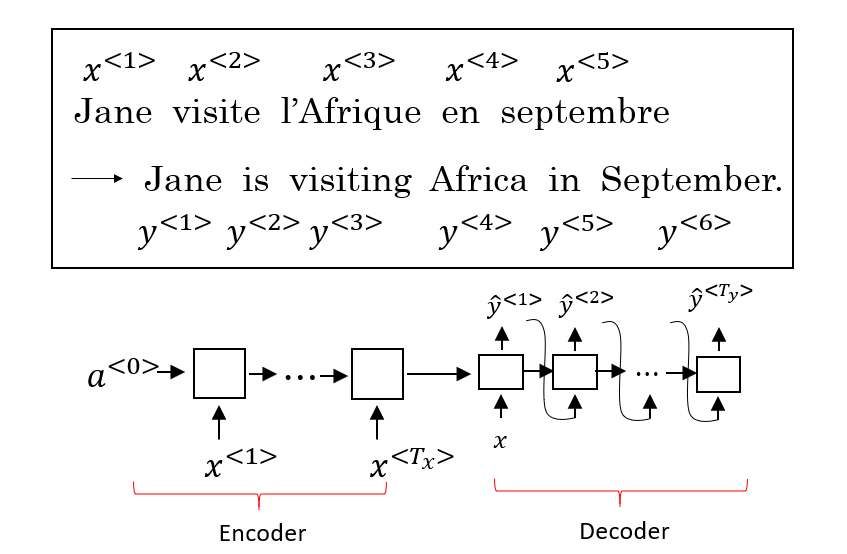
序列模型和注意力机制
序列模型和注意力机制Seq2Seq 模型 Seq2Seq(Sequence-to-Sequence) 模型能够应用于机器翻译、语音识别等各种序列到序列的转换问题。一个 Seq2Seq 模型包含 编码器(Encoder) 和 解码器(Decoder) 两部分,它们通常是两个不同的 RNN。如下图所示,将编码器的输出作为解码器的输入,由解码器负责输出正确的翻译结果。 提出 Seq2Seq 模型的相关论文: Sutskever et al., 2014. Sequence to sequence learning with neural networks Cho et al., 2014. Learning phrase representaions using RNN encoder-decoder for statistical machine translation 这种编码器-解码器的结构也可以用于图像描述(Image captioning)。将 AlexNet 作为编码器,最后一层的 Softmax 换成一个 RNN 作为解码器,网络的输出序列就是对图像的一个描...
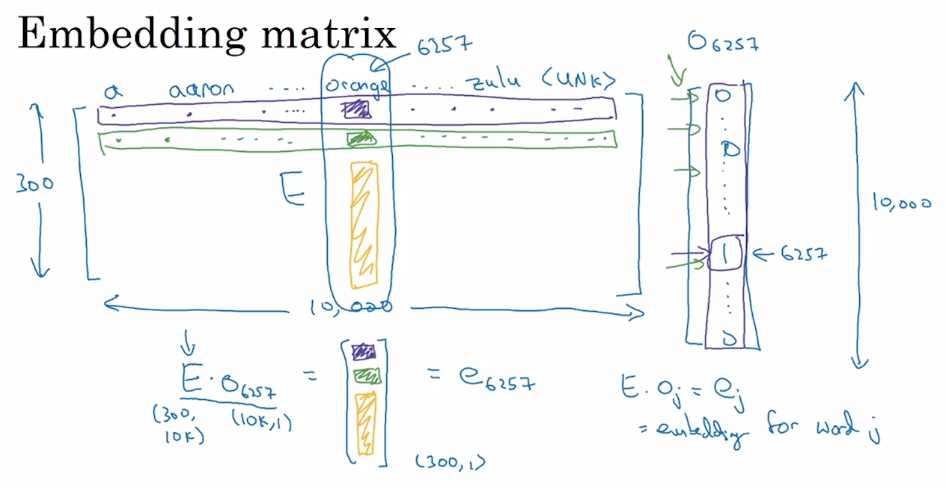
自然语言处理与词嵌入
自然语言处理与词嵌入1 词嵌入和词汇表征 one-hot 向量将每个单词表示为完全独立的个体,不同词向量都是正交的,因此单词间的相似度无法体现。 换用特征化表示方法能够解决这一问题。我们可以通过用语义特征作为维度来表示一个词,因此语义相近的词,其词向量也相近。 将高维的词嵌入“嵌入”到一个二维空间里,就可以进行可视化。常用的一种可视化算法是 t-SNE 算法。在通过复杂而非线性的方法映射到二维空间后,每个词会根据语义和相关程度聚在一起。 相关论文:van der Maaten and Hinton., 2008. Visualizing Data using t-SNE 词嵌入(Word Embedding) 是 NLP 中语言模型与表征学习技术的统称,概念上而言,它是指把一个维数为所有词的数量的高维空间(one-hot 形式表示的词)“嵌入”到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量。对大量词汇进行词嵌入后获得的词向量,可用于完成 命名实体识别(Named Entity Recognition) 等任务。 2 使用词嵌入与迁移学习 用...
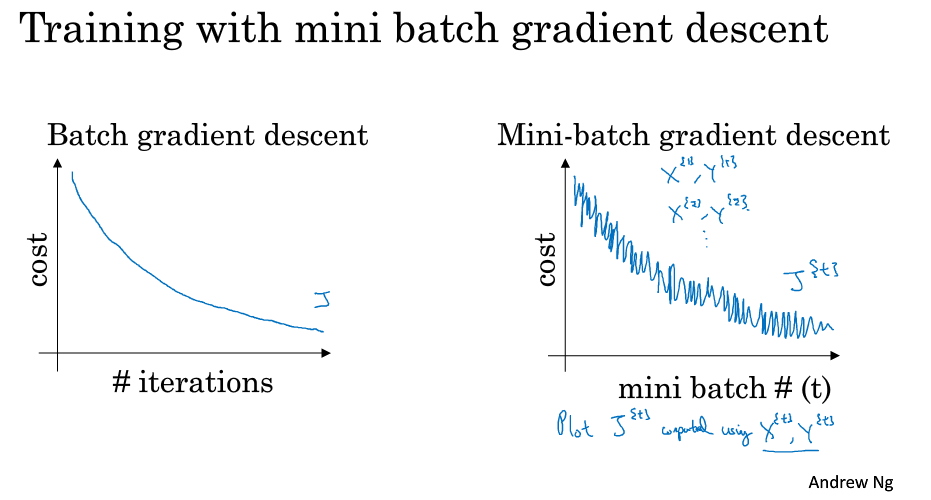
02mini-batch梯度下降
# mini-batch优化算法 > 深度学习难以在大数据领域发挥最大效果的一个原因是,在巨大的数据集基础上进行训练速度很慢。而优化算法能够帮助快速训练模型,大大提高效率。 ## 1 mini-batch梯度下降方法 ### batch 梯度下降法 * **batch 梯度下降法**(批梯度下降法,我们之前一直使用的梯度下降法)是最常用的梯度下降形式,即同时处理整个训练集。其在更新参数时使用所有的样本来进行更新。 * 对整个训练集进行梯度下降法的时候,我们必须处理整个训练数据集,然后才能进行一步梯度下降,即每一步梯度下降法需要对整个训练集进行一次处理,如果训练数据集很大的时候,处理速度就会比较慢。 * 但是如果每次处理训练数据的一部分即进行梯度下降法,则我们的算法速度会执行的更快。而处理的这些一小部分训练子集即称为**mini-batch**。 ### Mini-Batch 梯度下降法 * **Mini-Batch 梯度下降法**(小批量梯度下降法)每次同时处理单个的 mini-batch,其他与 batch 梯度下降法一致。 * 使用 batch 梯度下降法,...

03超参数调试、Batch正则化和程序框架
超参数调试、Batch 正则化和程序框架超参数调试处理超参数重要程度排序 最重要: 学习率 α; 其次重要: β:动量衰减参数,常设置为 0.9; #hidden units:各隐藏层神经元个数; mini-batch 的大小; 再次重要: β1,β2,ϵ:Adam 优化算法的超参数,常设为 0.9、0.999、$10^{-8}$; #layers:神经网络层数; decay_rate:学习衰减率; 调参技巧 随机选择点(而非均匀选取),用这些点实验超参数的效果。这样做的原因是我们提前很难知道超参数的重要程度,可以通过选择更多值来进行更多实验; 由粗糙到精细:聚焦效果不错的点组成的小区域,在其中更密集地取值,以此类推; 选择合适的范围 对于学习率 α,用对数标尺而非线性轴更加合理:0.0001、0.001、0.01、0.1 等,然后在这些刻度之间对log值进行均匀选择。 对于 β,取 0.9 就相当于在 10 个值中计算平均值,而取 0.999 就相当于在 1000 个值中计算平均值。可以考虑给 1-β 取值,这样就和取学习率类似了。 上述操作的原因是当 β...




