
00神经网络简介
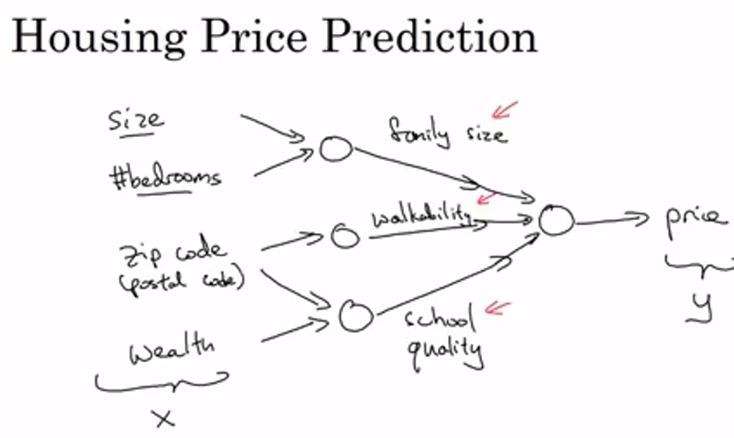
神经网络简介 必须得明白,吴恩达在通过什么角度,构建神经网络的基础知识。 什么是神经网络 神经网络分层 输入层—-隐藏层—-输出层 神经元输入层只有一个参数:激活值。输出层、隐藏层神经元有三个参数: 权重:指的是和输入层某个神经元的紧密关系。联系越紧密这个值越大($W$)。 激活值:输入的值乘以权重,然后相加。$z = W^T*X+bias$ 偏置:表示输入的截距,bias。 计算过程 正向过程(forward pass)或者叫正向传播步骤(forward propagation step) 反向过程(backward pass)或者叫反向传播步骤(backward propagation step)。 向量化 向量化 实现一个神经网络时,如果需要遍历整个训练集,并不需要直接使用 for 循环。采用向量化的方法代替for 循环 用神经网络进行监督学习应用领域 房屋价格预测-ANN普通神经网络,多维度特征 图像-CNN卷积神经网络,二维像素 声音-RNN循环神经网络,一维实践序列 翻译-RNNs循环神经网络 不同的神经网络 监督学习 结构化数据:数据...
01神经网络基础
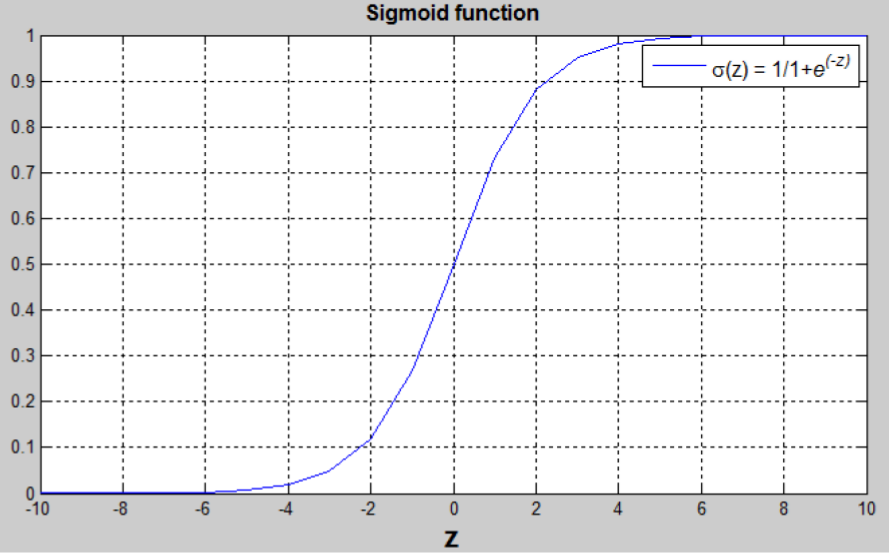
神经网络基础 介绍神经网络的编程基础。看完视频,在总结这一部分。每一个视频,完成开始做笔记。 1 识别图片上的猫问题定义 场景定义:监督学习。图像识别领域。非结构化数据输入。 问题定义:分类问题。 算法定义:logistics回归。 问题描述 输入的特征向量:$x \in R^{n_x}$,其中 ${n_x}$是特征数量; 输出的标签,用于训练的标签:$y \in 0,1$ 训练集:${(x^{(1)},y^{(1)}),\dots,(x^{(m)},y^{(m)})}$紧凑矩阵表示训练集。约定使用列向量。 2 Logistic回归模型 Logistic 回归是一个用于二分分类的算法。 模型定义-假设函数 权重:$w \in R^{n_x}$ 偏置: $b \in R$ 输出:$\hat{y} = \sigma(w^Tx+b)$ Sigmoid 函数:$$s = \sigma(w^Tx+b) = \sigma(z) = \frac{1}{1+e^{-z}}$$ 将 $w^Tx+b$ 约束在 [0, 1] 间...
02浅层神经网络
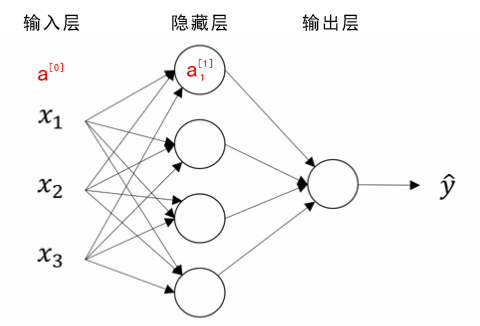
浅层神经网络 ReLU,recfied linear unit修正线性单元 神经网络表示 竖向堆叠起来的输入特征被称作神经网络的输入层(the input layer)。 神经网络的 隐藏层(a hidden layer) 。“隐藏”的含义是 在训练集中 ,这些中间节点的真正数值是无法看到的。 输出层(the output layer) 负责输出预测值。 下图被称为双层神经网络。包括隐藏层和输出层,一般不考虑输入层。 如图是一个双层神经网络,也称作单隐层神经网络(a single hidden layer neural network)。当我们计算网络的层数时,通常不考虑输入层,因此图中隐藏层是第一层,输出层是第二层。 约定俗成的符号表示: $x$表示其中一个样本。$a^{0}$第一个样本输入层的激活值。$a^{1}$第一个样本隐藏层产生激活值。 $n^{[i]}$表示第i层的单元数量。 $z=W^T * a+b$,$x$表示单个样本,$z$表示求和值,$W$权重,$a$上一层产生的激活值,$b$偏置单元。 $Z=W^T * A+b$,样本向...
03深层神经网络
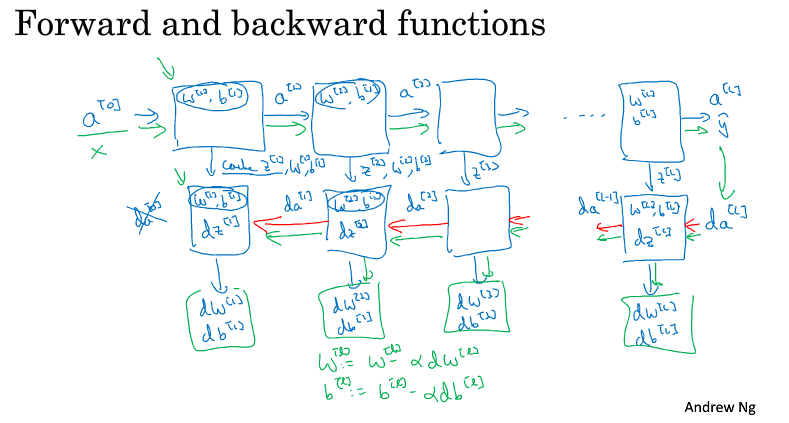
深层神经网络深层神经网络的符号表示 $L=4$,神经网络有四层。 $n^{[l]}$,l层上单元的个数。 $a^{[l]}$,l层上激活函数的输出,激活值。 x表示输入的特征。 $a^{[l]}g^{[l]}(z^{[l]})$l层的激活函数 $z^{[l]}=W^{[l]T}a^{[l-1]}+b^{[l]}$,l层的求和 深层网络中的前向和反向传播前向传播输入:$a^{[l−1]}$ 输出:$a^{[l]}$,cache($z^{[l]}$) 公式: $$Z^{[l]}=W^{[l]}\cdot a^{[l-1]}+b^{[l]}$$ $$a^{[l]}=g^{[l]}(Z^{[l]})$$ 反向传播输入:$da^{[l]}$ 输出:$da^{[l-1]}$,$dW^{[l]}$,$db^{[l]}$ 公式: $$dZ^{[l]}=da^{[l]}*g^{[l]}{‘}(Z^{[l]})$$ $$dW^{[l]}=dZ^{[l]}\cdot a^{[l-1]}$$ $$db^{[l]}=dZ^{[l]}...

11_Convolutional Neural Network part1
Convolutional Neural network(part 1) CNN常常被用在影像处理上,它的theory base就是三个property,和两个架构convolution 架构:针对property 1和property 2max pooling架构:针对property 3 Why CNN for Image?CNN V.s. DNN我们当然可以用一般的neural network来做影像处理,不一定要用CNN,比如说,你想要做图像的分类,那你就去train一个neural network,它的input是一张图片,你就用里面的pixel来表示这张图片,也就是一个很长很长的vector,而output则是由图像类别组成的vector,假设你有1000个类别,那output就有1000个dimension 但是,我们现在会遇到的问题是这样子:实际上,在train neural network的时候,我们会有一种期待说,在这个network structure里面的每一个neuron,都应该代表了一个最基本的classifier;事实上,在文献上,根据训练的结果,...

10_Keras
Keras2.0Why Keras你可能会问,为什么不学TensorFlow呢?明明tensorflow才是目前最流行的machine learning库之一啊。其实,它并没有那么好用,tensorflow和另外一个功能相近的toolkit theano,它们是非常flexible的,你甚至可以把它想成是一个微分器,它完全可以做deep learning以外的事情,因为它的作用就是帮你算微分,拿到微分之后呢,你就可以去算gradient descent之类,而这么flexible的toolkit学起来是有一定的难度的,你没有办法在半个小时之内精通这个toolkit 但是另一个toolkit——Keras,你是可以在数十分钟内就熟悉并精通它的,然后用它来implement一个自己的deep learning,Keras其实是tensorflow和theano的interface,所以用Keras就等于在用tensorflow,只是有人帮你把操纵tensorflow这件事情先帮你写好 所以Keras是比较容易去学习和使用的,并且它也有足够的弹性,除非你自己想要做deep learni...

14_Why Deep
Why Deep? 本文主要围绕Deep这个关键词展开,重点比较了shallow learning和deep learning的区别:shallow:不考虑不同input之间的关联,针对每一种class都设计了一个独立的model检测deep:考虑了input之间的某些共同特征,所有class用同个model分类,share参数,modularization思想,hierarchy架构,更有效率地使用data和参数 Shallow V.s. DeepDeep is Better?我们都知道deep learning在很多问题上的表现都是比较好的,越deep的network一般都会有更好的performance 那为什么会这样呢?有一种解释是: 一个network的层数越多,参数就越多,这个model就越复杂,它的bias就越小,而使用大量的data可以降低这个model的variance,performance当然就会更好 如下图所示,随着layer层数从1到7,得到的error rate不断地降低,所以有人就认为,deep learning的表现这么好,完全就是用大量的d...

12_Convolutional Neural Network part2
Convolutional Neural Network part2 人们常常会说,deep learning就是一个黑盒子,你learn完以后根本就不知道它得到了什么,所以会有很多人不喜欢这种方法,这篇文章就讲述了三个问题:What does CNN do?Why CNN?How to design CNN? What does CNN learn?what is intelligent如果今天有一个方法,它可以让你轻易地理解为什么这个方法会下这样的判断和决策的话,那其实你会觉得它不够intelligent;它必须要是你无法理解的东西,这样它才够intelligent,至少你会感觉它很intelligent 所以,大家常说deep learning就是一个黑盒子,你learn出来以后,根本就不知道为什么是这样子,于是你会感觉它很intelligent,但是其实还是有很多方法可以分析的,今天我们就来示范一下怎么分析CNN,看一下它到底学到了什么 要分析第一个convolution的filter是比较容易的,因为第一个convolution layer里面,每一个filter就...

13_Tips for Deep Learning
Tips for Deep Learning 本文会顺带解决CNN部分的两个问题:1、max pooling架构中用到的max无法微分,那在gradient descent的时候该如何处理?2、L1 的Regression到底是什么东西 本文的主要思路:针对training set和testing set上的performance分别提出针对性的解决方法1、在training set上准确率不高: new activation function:ReLU、Maxout adaptive learning rate:Adagrad、RMSProp、Momentum、Adam2、在testing set上准确率不高:Early Stopping、Regularization or Dropout Recipe of Deep Learningthree step of deep learningRecipe,配方、秘诀,这里指的是做deep learning的流程应该是什么样子 我们都已经知道了deep learning的三个步骤 define the function ...

15_Semi-supervised Learning
Semi-supervised Learning 半监督学习(semi-supervised learning)1、introduction2、Semi-supervised Learning for Generative Model3、Low-density Separation Assumption:非黑即白4、Smoothness Assumption:近朱者赤,近墨者黑5、Better Representation:去芜存菁,化繁为简 IntroductionSupervised Learning:$(x^r,\hat y^r)$$_{r=1}^R$ training data中,每一组data都有input $x^r$和对应的output $y^r$ Semi-supervised Learning:${(x^r,\hat y^r)}{r=1}^R$} + ${x^u}{u=R}^{R+U}$ training data中,部分data没有标签,只有input $x^u$ 通常遇到的场景是,无标签的数据量远大于有标签的数据量,...




