

16_Unsupervised Learning Introduction
Unsupervised Learning: IntroductionUnsupervised Learning无监督学习(Unsupervised Learning)可以分为两种: 化繁为简 聚类(Clustering) 降维(Dimension Reduction) 无中生有(Generation) 对于无监督学习(Unsupervised Learning)来说,我们通常只会拥有$(x,\hat y)$中的$x$或$\hat y$,其中: 化繁为简就是把复杂的input变成比较简单的output,比如把一大堆没有打上label的树图片转变为一棵抽象的树,此时training data只有input $x$,而没有output $\hat y$ 无中生有就是随机给function一个数字,它就会生成不同的图像,此时training data没有input $x$,而只有output $\hat y$ ClusteringIntroduction聚类,顾名思义,就是把相近的样本划分为同一类,比如对下面这些没有标签的image进行分类,手动打上cluster 1、...

17_Unsupervised Learning PCA part1
Unsupervised Learning: PCA(Ⅰ) 本文将主要介绍PCA算法的数学推导过程 上一篇文章提到,PCA算法认为降维就是一个简单的linear function,它的input x和output z之间是linear transform,即$z=Wx$,PCA要做的,就是根据$x$把W给找出来($z$未知) PCA for 1-D为了简化问题,这里我们假设z是1维的vector,也就是把x投影到一维空间,此时w是一个row vector $z_1=w^1\cdot x$,其中$w^1$表示$w$的第一个row vector,假设$w^1$的长度为1,即$||w^1||_2=1$,此时$z_1$就是$x$在$w^1$方向上的投影 那我们到底要找什么样的$w^1$呢? 假设我们现在已有的宝可梦样本点分布如下,横坐标代表宝可梦的攻击力,纵坐标代表防御力,我们的任务是把这个二维分布投影到一维空间上 我们希望选这样一个$w^1$,它使得$x$经过投影之后得到的$z_1$分布越大越好,也就是说,经过这个投影后,不同样本点之间的区别,应该仍然是...

18_Unsupervised Learning PCA part2
Unsupervised Learning: PCA(Ⅱ) 本文主要从组件和SVD分解的角度介绍PCA,并描述了PCA的神经网络实现方式,通过引入宝可梦、手写数字分解、人脸图像分解的例子,介绍了NMF算法的基本思想,此外,还提供了一些PCA相关的降维算法和论文 Reconstruction Component假设我们现在考虑的是手写数字识别,这些数字是由一些类似于笔画的basic component组成的,本质上就是一个vector,记做$u_1,u_2,u_3,…$,以MNIST为例,不同的笔画都是一个28×28的vector,把某几个vector加起来,就组成了一个28×28的digit 写成表达式就是:$x≈c_1u^1+c_2u^2+…+c_ku^k+\bar x$ 其中$x$代表某张digit image中的pixel,它等于k个component的加权和$\sum c_iu^i$加上所有image的平均值$\bar x$ 比如7就是$x=u^1+u^3+u^5$,我们可以用$\left [\begin{matrix}c_1\ c_2\ c_3…c_k \e...

19_Matrix Factorization
Matrix Factorization 本文将通过一个详细的例子分析矩阵分解思想及其在推荐系统上的应用 Introduction接下来介绍矩阵分解的思想:有时候存在两种object,它们之间会受到某种共同潜在因素(latent factor)的操控,如果我们找出这些潜在因素,就可以对用户的行为进行预测,这也是推荐系统常用的方法之一 假设我们现在去调查每个人购买的公仔数目,ABCDE代表5个人,每个人或者每个公仔实际上都是有着傲娇的属性或天然呆的属性 我们可以用vector去描述人和公仔的属性,如果某个人的属性和某个公仔的属性是match的,即他们背后的vector很像(内积值很大),这个人就会偏向于拥有更多这种类型的公仔 matrix expression但是,我们没有办法直接观察某个人背后这些潜在的属性,也不会有人在意一个肥宅心里想的是什么,我们同样也没有办法直接得到动漫人物背后的属性;我们目前有的,只是动漫人物和人之间的关系,即每个人已购买的公仔数目,我们要通过这个关系去推测出动漫人物与人背后的潜在因素(latent factor) 我们可以把每个人的属性用vec...
1_Introduction
Introduction如何定义一个机器学习的问题 机器学习的本质,是机器自动寻找输入和输出之间的函数function,建立输入和输出的关系。 根据机器学习的输入input数据集data set,定义学习的场景 有标签的数据集:监督学习supervisor learning 没有标签的数据集:无监督学习unsupervisor learning、生成对抗网络GAN 标签不全的数据集:半监督学习semi-supervisor learning 特征不一致的数据集:迁移学习transfer learning 没有数据:强化学习reinforcement learning 根据机器学习的输出output,来定义一个问题或任务task 连续的数值:回归问题regression 离散的数值:分类问题classification 结构化数值:生成问题generation(例如一张斑马的图片、一段翻译的结果、一篇文章的总结,生成结构化的数据,结构化学习) 选择合适的机器学习算法集合,评估机器学习算法的好坏 定义损失函数loss function 使用梯度下降优化算法,减小损失函数...

20_Unsupervised Learning Word Embedding
Unsupervised Learning: Word Embedding 本文介绍NLP中词嵌入(Word Embedding)相关的基本知识,基于降维思想提供了count-based和prediction-based两种方法,并介绍了该思想在机器问答、机器翻译、图像分类、文档嵌入等方面的应用 Introduction词嵌入(word embedding)是降维算法(Dimension Reduction)的典型应用 那如何用vector来表示一个word呢? 1-of-N Encoding最传统的做法是1-of-N Encoding,假设这个vector的维数就等于世界上所有单词的数目,那么对每一个单词来说,只需要某一维为1,其余都是0即可;但这会导致任意两个vector都是不一样的,你无法建立起同类word之间的联系 Word Class还可以把有同样性质的word进行聚类(clustering),划分成多个class,然后用word所属的class来表示这个word,但光做clustering是不够的,不同class之间关联依旧无法被有效地表达出来 Word Embed...

21_Unsupervised Learning Neighbor Embedding
Unsupervised Learning: Neighbor Embedding 本文介绍了非线性降维的一些算法,包括局部线性嵌入LLE、拉普拉斯特征映射和t分布随机邻居嵌入t-SNE,其中t-SNE特别适用于可视化的应用场景 PCA和Word Embedding介绍了线性降维的思想,而Neighbor Embedding要介绍的是非线性的降维 Manifold Learning样本点的分布可能是在高维空间里的一个流行(Manifold),也就是说,样本点其实是分布在低维空间里面,只是被扭曲地塞到了一个高维空间里 地球的表面就是一个流行(Manifold),它是一个二维的平面,但是被塞到了一个三维空间里 在Manifold中,只有距离很近的点欧氏距离(Euclidean Distance)才会成立,而在下图的S型曲面中,欧氏距离是无法判断两个样本点的相似程度的 而Manifold Learning要做的就是把这个S型曲面降维展开,把塞在高维空间里的低维空间摊平,此时使用欧氏距离就可以描述样本点之间的相似程度 Locally Linear Embedding局部线性嵌入,l...
23_Unsupervised Learning Generation
Unsupervised Learning: Generation 本文将简单介绍无监督学习中的生成模型,包括PixelRNN、VAE和GAN,以后将会有一个专门的系列介绍对抗生成网络GAN Introduction正如Richard Feynman所说,“What I cannot create, I do not understand”,我无法创造的东西,我也无法真正理解,机器可以做猫狗分类,但却不一定知道“猫”和“狗”的概念,但如果机器能自己画出“猫”来,它或许才真正理解了“猫”这个概念 这里将简要介绍:PixelRNN、VAE和GAN这三种方法 PixelRNNIntroductionRNN可以处理长度可变的input,它的基本思想是根据过去发生的所有状态去推测下一个状态 PixelRNN的基本思想是每次只画一个pixel,这个pixel是由过去所有已产生的pixel共同决定的 这个方法也适用于语音生成,可以用前面一段的语音去预测接下来生成的语音信号 总之,这种方法的精髓在于根据过去预测未来,画出来的图一般都是比较清晰的 pokemon creation用这个方法去...
22_Unsupervised Learning Deep Auto-encoder
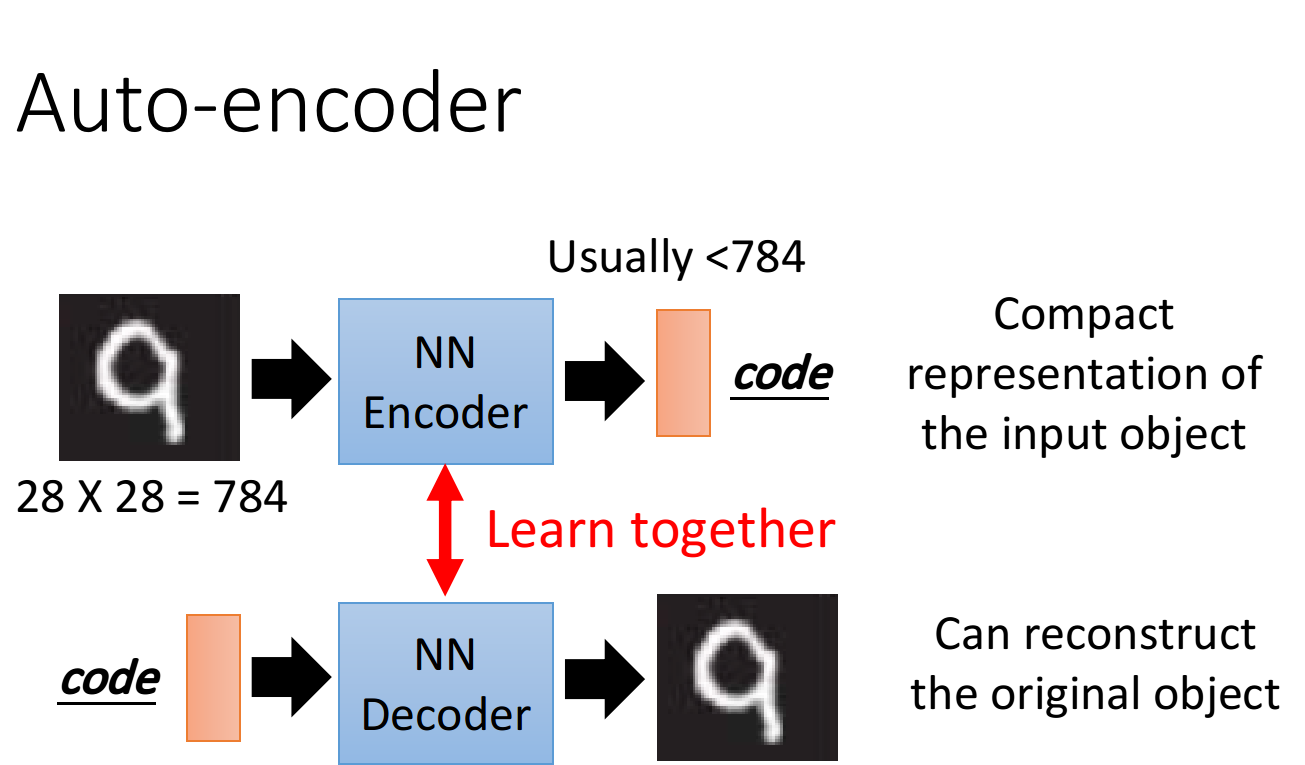
Unsupervised Learning: Deep Auto-encoder 文本介绍了自编码器的基本思想,与PCA的联系,从单层编码到多层的变化,在文字搜索和图像搜索上的应用,预训练DNN的基本过程,利用CNN实现自编码器的过程,加噪声的自编码器,利用解码器生成图像等内容 IntroductionAuto-encoder本质上就是一个自我压缩和解压的过程,我们想要获取压缩后的code,它代表了对原始数据的某种紧凑精简的有效表达,即降维结果,这个过程中我们需要: Encoder(编码器),它可以把原先的图像压缩成更低维度的向量 Decoder(解码器),它可以把压缩后的向量还原成图像 注意到,Encoder和Decoder都是Unsupervised Learning,由于code是未知的,对Encoder来说,我们手中的数据只能提供图像作为NN的input,却不能提供code作为output;对Decoder来说,我们只能提供图像作为NN的output,却不能提供code作为input 因此Encoder和Decoder单独拿出一个都无法进行训练,我们需要把它们连...

24_Transfer Learning
Transfer Learning 迁移学习,主要介绍共享layer的方法以及属性降维对比的方法 Introduction迁移学习,transfer learning,旨在利用一些不直接相关的数据对完成目标任务做出贡献 not directly related以猫狗识别为例,解释“不直接相关”的含义: input domain是类似的,但task是无关的 比如输入都是动物的图像,但这些data是属于另一组有关大象和老虎识别的task input domain是不同的,但task是一样的 比如task同样是做猫狗识别,但输入的是卡通类型的图像 compare with real life事实上,我们在日常生活中经常会使用迁移学习,比如我们会把漫画家的生活自动迁移类比到研究生的生活 overview迁移学习是很多方法的集合,这里介绍一些概念: Target Data:和task直接相关的data Source Data:和task没有直接关系的data 按照labeled data和unlabeled data又可以划分为四种: Case 1这里ta...




