

25_Support Vector Machine
Support Vector Machine支持向量机(SVM)有两个特点:SVM=铰链损失(Hinge Loss)+核技巧(Kernel Method) 注:建议先看这篇博客了解SVM基础知识后再看本文的分析 Hinge LossBinary Classification先回顾一下二元分类的做法,为了方便后续推导,这里定义data的标签为-1和+1 当$f(x)>0$时,$g(x)=1$,表示属于第一类别;当$f(x)<0$时,$g(x)=-1$,表示属于第二类别 原本用$\sum \delta(g(x^n)\ne \hat y^n)$,不匹配的样本点个数,来描述loss function,其中$\delta=1$表示$x$与$\hat y$相匹配,反之$\delta=0$,但这个式子不可微分,无法使用梯度下降法更新参数 因此使用近似的可微分的$l(f(x^n),\hat y^n)$来表示损失函数 下图中,横坐标为$\hat y^n f(x)$,我们希望横坐标越大越好: 当$\hat y^n>...

27_Recurrent Neural Network part2
Recurrent Neural Network(Ⅱ) 上一篇文章介绍了RNN的基本架构,像这么复杂的结构,我们该如何训练呢? Learning TargetLoss Function依旧是Slot Filling的例子,我们需要把model的输出$y^i$与映射到slot的reference vector求交叉熵,比如“Taipei”对应到的是“dest”这个slot,则reference vector在“dest”位置上值为1,其余维度值为0 RNN的output和reference vector的cross entropy之和就是损失函数,也是要minimize的对象 需要注意的是,word要依次输入model,比如“arrive”必须要在“Taipei”前输入,不能打乱语序 Training有了损失函数后,训练其实也是用梯度下降法,为了计算方便,这里采取了反向传播(Backpropagation)的进阶版,Backpropagation through time,简称BPTT算法 BPTT算法与BP算法非常类似,只是多了一些时间维度上的信息,这里不做详细介绍 不...

26_Recurrent Neural Network part1
Recurrent Neural Network(Ⅰ) RNN,或者说最常用的LSTM,一般用于记住之前的状态,以供后续神经网络的判断,它由input gate、forget gate、output gate和cell memory组成,每个LSTM本质上就是一个neuron,特殊之处在于有4个输入:$z$和三门控制信号$z_i$、$z_f$和$z_o$,每个时间点的输入都是由当前输入值+上一个时间点的输出值+上一个时间点cell值来组成 IntroductionSlot Filling在智能客服、智能订票系统中,往往会需要slot filling技术,它会分析用户说出的语句,将时间、地址等有效的关键词填到对应的槽上,并过滤掉无效的词语 词汇要转化成vector,可以使用1-of-N编码,word hashing或者是word vector等方式,此外我们可以尝试使用Feedforward Neural Network来分析词汇,判断出它是属于时间或是目的地的概率 但这样做会有一个问题,该神经网络会先处理“arrive”和“leave”这两个词汇,然后再处理“Taipei”,这...

2_Regression Case Study
Regression:Case Study回归问题 预测 给出特征,预测特征的结果 推荐 一般包括两组对象。描述两组对象之间的关联性。 例如读者+文章的推荐系统。读者的特征敏感度$\theta$+文章特征$x_i$。基于个人浏览记录和文章特征的内容推荐系统,给定后者,训练读者的特征敏感度,然后推荐;基于文章被浏览的记录和读者特征的内容推荐系统,给定前者,训练文章本身的特征,然后推荐;基于协同过滤算法,前者后者都没有,进行推荐。 机器学习的约定 使用上标代表数据集中单条数据的定位。 使用下表代表单条数据中组成元素的定位。 假设函数,即训练模型。 损失函数,是关于参数的函数。 如何实现一个机器学习算法 定义模型,给出假设函数,关于输入输出的函数。 定义损失,给出代价函数,关于参数的函数,输入输出用数据集代替。 梯度下降,最小化代价函数。 问题的导入:预测宝可梦的CP值Estimating the Combat Power(CP) of a pokemon after evolution 我们期望根据已有的宝可梦进化前后的信息,来预测某只宝可梦进化后的cp值的大小 确定...
3_Regression demo(Adagrad)
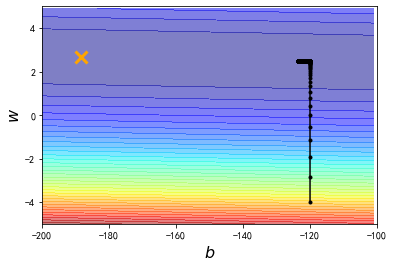
Regression:linear model 这里用的是 Adagrad ,接下来的课程会再细讲,这里只是想显示 gradient descent 实作起来没有想像的那么简单,还有很多小技巧要注意 这里采用最简单的linear model:y_data=b+w*x_data 我们要用gradient descent把b和w找出来 当然这个问题有closed-form solution,这个b和w有更简单的方法可以找出来;那我们假装不知道这件事,我们练习用gradient descent把b和w找出来 数据准备:12345# 假设x_data和y_data都有10笔,分别代表宝可梦进化前后的cp值x_data=[338.,333.,328.,207.,226.,25.,179.,60.,208.,606.]y_data=[640.,633.,619.,393.,428.,27.,193.,66.,226.,1591.]# 这里采用最简单的linear model:y_data=b+w*x_data# 我们要用gradient descent把b和w找出来 计算梯度微...

5_Gradient Descent
Gradient DescentReview前面预测宝可梦cp值的例子里,已经初步介绍了Gradient Descent的用法: In step 3, we have to solve the following optimization problem: $\theta^{*}=\arg \underset{\theta}{\min} L(\theta) \quad$ L : loss function$\theta:$ parameters(上标表示第几组参数,下标表示这组参数中的第几个参数) 假设$\theta$是参数的集合:Suppose that $\theta$ has two variables $\left{\theta_{1}, \theta_{2}\right}$ 随机选取一组起始的参数:Randomly start at $\theta^{0}=\left[\begin{array}{l}{\theta_{1}^{0}} \ {\theta_{2}^{0}}\end{array}\right] ...

4_Where does the error come from
Where does the error come from?Review之前有提到说,不同的function set,也就是不同的model,它对应的error是不同的;越复杂的model,也许performance会越差,所以今天要讨论的问题是,这个error来自什么地方 error due to ==bias== error due to ==variance== 了解error的来源其实是很重要的,因为我们可以针对它挑选适当的方法来improve自己的model,提高model的准确率,而不会毫无头绪 #### 抽样分布 $\widehat{y}$和$y^*$ 真值和估测值$\widehat{y}$表示那个真正的function,而$f^*$表示这个$\widehat{f}$的估测值estimator 就好像在打靶,$\widehat{f}$是靶的中心点,收集到一些data做training以后,你会得到一个你觉得最好的function即$f^$,这个$f^$落在靶上的某个位置,它跟靶...

6_Classification
Classification: Probabilistic Generative ModelClassification概念描述分类问题是找一个function,它的input是一个object,它的输出是这个object属于哪一个class 还是以宝可梦为例,已知宝可梦有18种属性,现在要解决的分类问题就是做一个宝可梦种类的分类器,我们要找一个function,这个function的input是某一只宝可梦,它的output就是这只宝可梦属于这18类别中的哪一个type 输入数值化对于宝可梦的分类问题来说,我们需要解决的第一个问题就是,怎么把某一只宝可梦当做function的input? ==要想把一个东西当做function的input,就需要把它数值化== 特性数值化:用一组数字来描述一只宝可梦的特性 比如用一组数字表示它有多强(total strong)、它的生命值(HP)、它的攻击力(Attack)、它的防御力(Defense)、它的特殊攻击力(Special Attack)、它的特殊攻击的防御力(Special defen...
8_Deep Learning
Deep LearningUps and downs of Deep Learning 1958:Perceptron(linear model),感知机的提出 和Logistic Regression类似,只是少了sigmoid的部分 1969:Perceptron has limitation,from MIT 1980s:Multi-layer Perceptron,多层感知机 和今天的DNN很像 1986:Backpropagation,反向传播 Hinton propose的Backpropagation 存在problem:通常超过3个layer的neural network,就train不出好的结果 1989: 1 hidden layer is “good enough”,why deep? 有人提出一个理论:只要neural network有一个hidden layer,它就可以model出任何的function,所以根本没有必要叠加很多个hidden layer,所以Multi-layer Perceptron的方法又坏掉了,这段时间Multi-l...
7_Logistic Regression
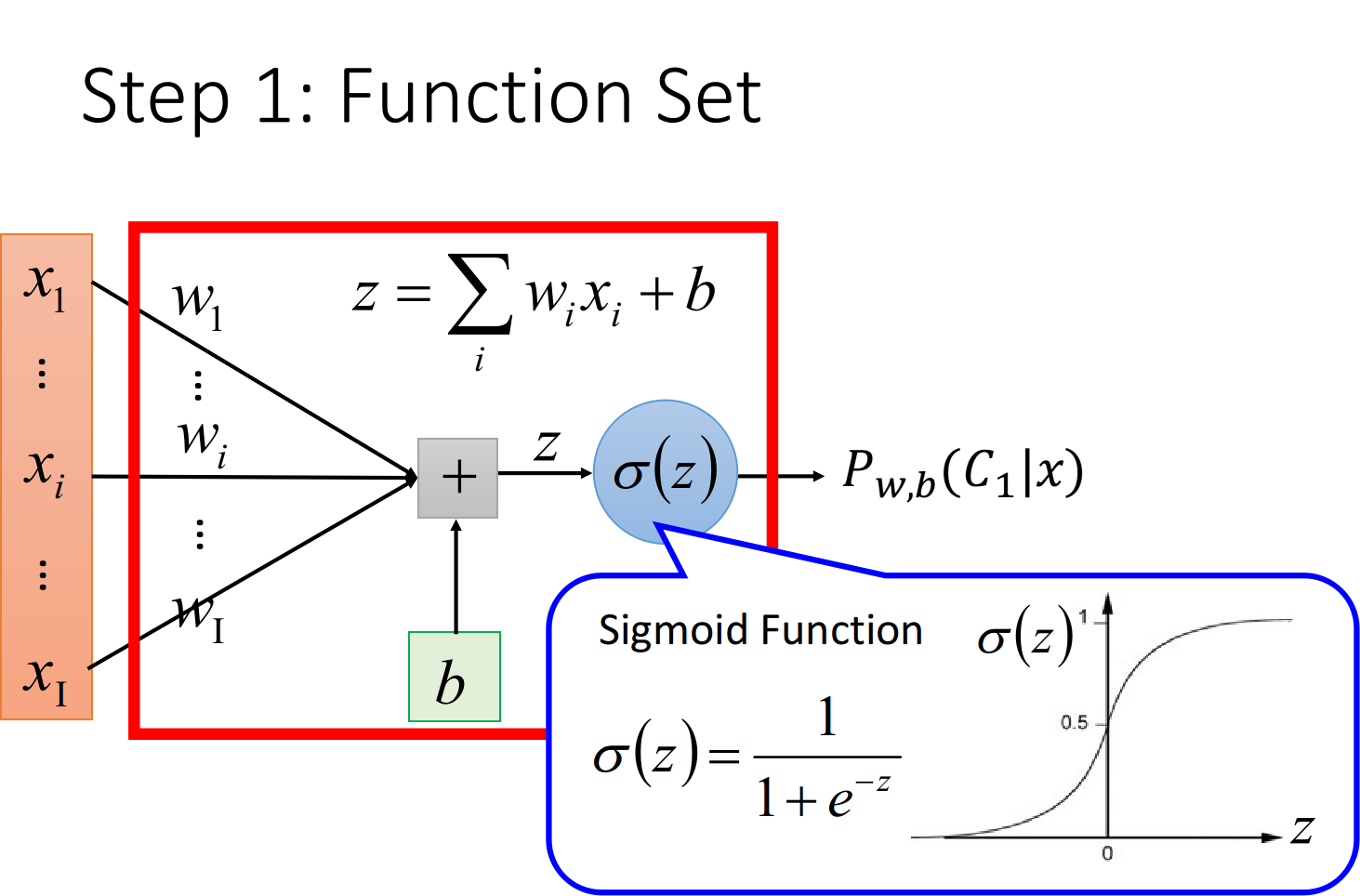
Logistic RegressionReview在classification这一章节,我们讨论了如何通过样本点的均值$u$和协方差$\Sigma$来计算$P(C_1),P(C_2),P(x|C_1),P(x|C_2)$,进而利用$P(C_1|x)=\frac{P(C_1)P(x|C_1)}{P(C_1)P(x|C_1)+P(C_2)P(x|C_2)}$计算得到新的样本点x属于class 1的概率,由于是二元分类,属于class 2的概率$P(C_2|x)=1-P(C_1|x)$ 之后我们还推导了$P(C_1|x)=\sigma(z)=\frac{1}{1+e^{-z}}$,并且在Gaussian的distribution下考虑class 1和class 2共用$\Sigma$,可以得到一个线性的z(其实很多其他的Probability model经过化简以后也都可以得到同样的结果)$$P_{w,b}(C_1|x)=\sigma(z)=\frac{1}{1+e^{-z}} \z&...




