
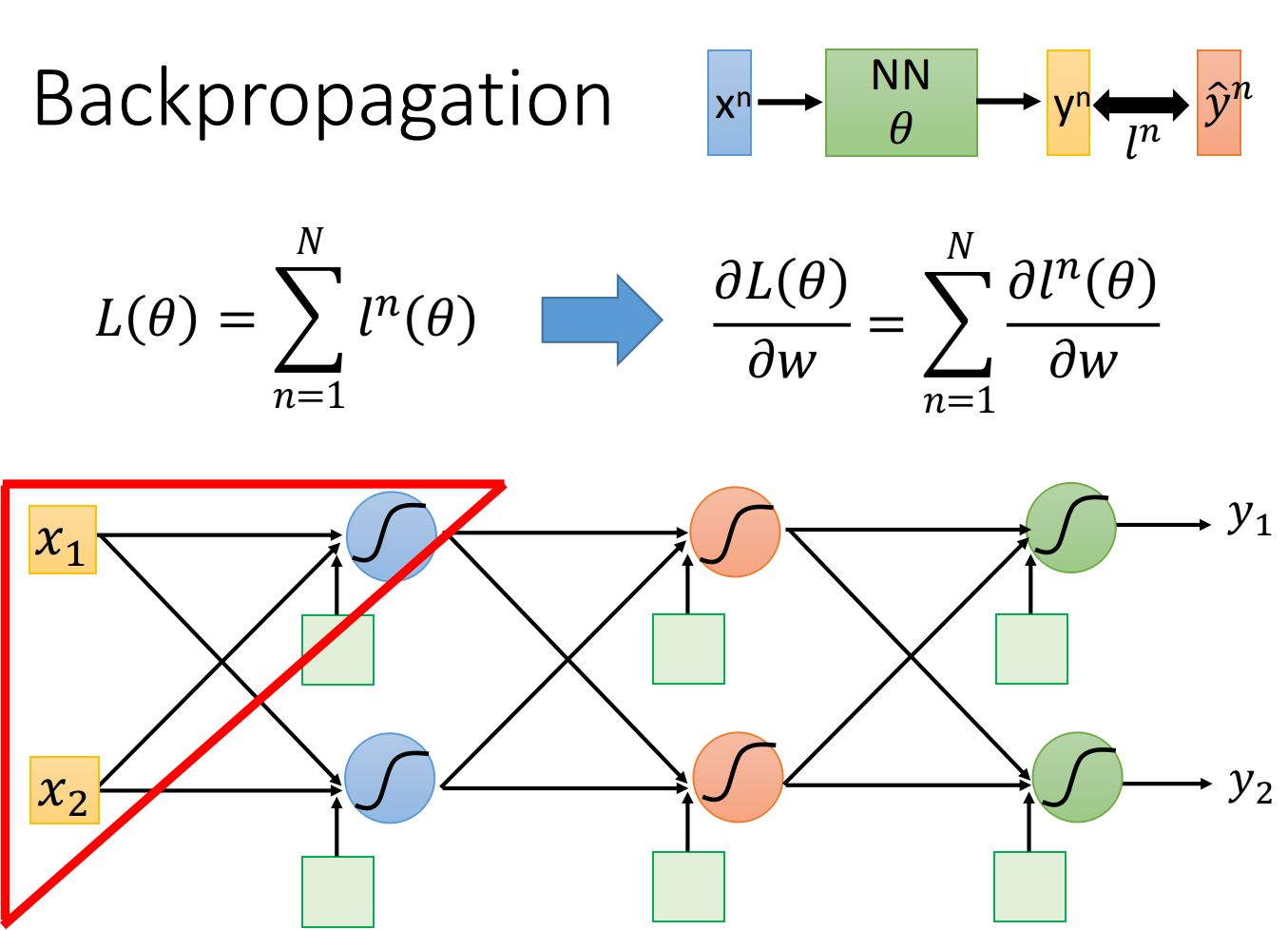
9_Backpropagation
Backpropagation Backpropagation(反向传播),就是告诉我们用gradient descent来train一个neural network的时候该怎么做,它只是求微分的一种方法,而不是一种新的算法 Gradient Descentgradient descent的使用方法,跟前面讲到的linear Regression或者是Logistic Regression是一模一样的,唯一的区别就在于当它用在neural network的时候,network parameters $\theta=w_1,w_2,…,b_1,b_2,…$里面可能会有将近million个参数 所以现在最大的困难是,如何有效地把这个近百万维的vector给计算出来,这就是Backpropagation要做的事情,所以Backpropagation并不是一个和gradient descent不同的training的方法,它就是gradient descent,它只是一个比较有效率的算法,让你在计算这个gradient的vector的时候更有效率 Chain RuleBack...

16推荐系统
推荐系统问题规划 电影和用户的评分相关性 使用用户对电影的评分,进行协同过滤的模型。 基于内容的推荐算法 主要思想: 基于用户浏览过的数据集,对用户尚未浏览的数据集进行评分。 假定我们已经知道,单个数据样本的特征标签。 通过多元线性回归+每个用户的历史数据集,训练得到每一个用户的线性回归参数$\theta$ 协同过滤 特征学习,自行学习要使用的特征。 没有考虑用户之间的关联性。首先通过用户对电影特征的喜爱程度,反向 基于浏览过同一个电影的用户数据,对电影进行评分。同样也是基于内容的。前者是基于用户浏览记录+电影特征判断用户对特征的的爱好,后者是通过电影被浏览的记录判断电影包含的特征。 123456789101112用户电影特征基于内容的推荐算法:用户-电影 + 电影-特征 = 用户-特征协同过滤: 用户-电影 + 用户-特征 = 电影-特征两者可以结合,进行循环训练,能够收敛到更好的模型。用户-特征 -> 电影-特征 -> 用户-特征 基于内容的推荐算法:已知用户-电影,电影-特征,求解用户-特征,用户-电影。 协同过滤:已知用户-电影,用户-特征,...
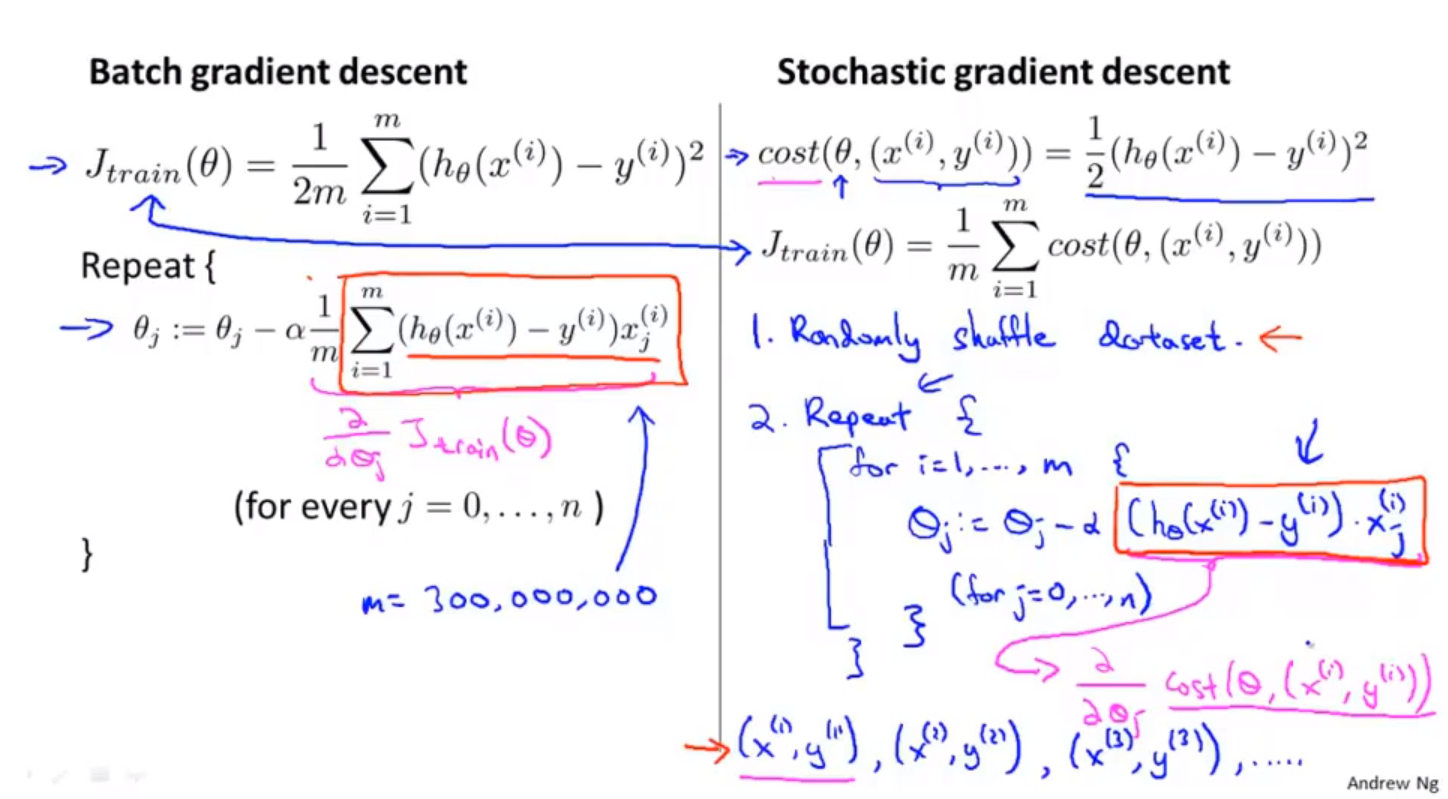
17大数据集
大数据集大数据集机器学习 通过大量数据,能够减少数据方差带来的模型误差。但不能解决模型偏差带来的模型误差。(有待考虑) 随机梯度下降算法 数据集很大的时候,普通梯度下降会变得困难。使用随机梯度下降,能够解决数据集过大的现象。 batch梯度下降。一次对所有的数据进行梯度下降。 随机梯度下降;stochastic gradient descent random shuffle example repeat gradient descent on one example 两种梯度下降算法对比 随机梯度下降算法过程 mini-batch 梯度下降算法 选取少量样本进行梯度下降。 需要有非常高效的向量化方法,对小范围内的数据进行求和运算 随机梯度下降的收敛问题 学习率一般是固定的参数,如果想让代价函数收敛在更小的位置,可以随着训练过程降低学习率。 保持固定的学习率能够方便调试。 在线机器学习 针对不断增加的连续的数据流。不断增加数据的网站,连续的数据流==> 在线机器学习。一边学习一边使用。 邮寄包裹的例子:用户的统计学特征、发货地、目的地、给出的...
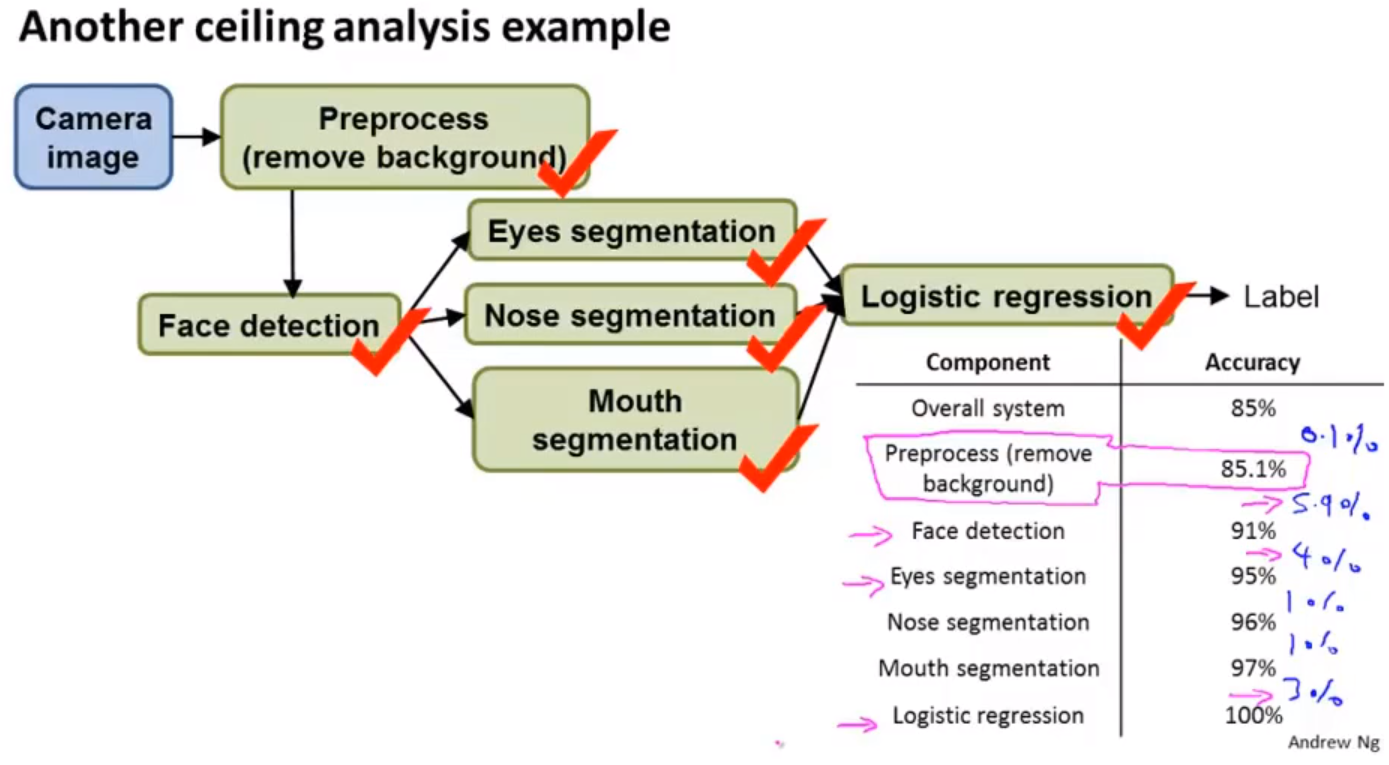
18案例Photo OCR
机器学习案例-Photo OCR问题描述 主要目的: 复杂的机器学习系统是如何组建出来的 机器学习流水线的概念。 如何分配机器学习资源 问题描述:照片的光学识别。 找出由文字的区域text detection 字符分割character segment 字符识别character classification 机器学习流水线photo ocr pipeline image -> text detection -> character segment -> character classification 将图片传入一系列机器学习组件,完成一系列任务。 滑动窗口 使用一个固定大小滑动窗口,在待检测的图片上遍历所有可能存在目标的区域。 调整滑动窗口的大小,将滑动窗口映射为固定大小,然后继续进行滑动,并检测窗口中是否存在目标。(100-50的区域,通过数据处理映射为50-25的检测单元,然后进行目标分析) 获取大量数据和人工数据人工合成数据 识别字体图片中:使用网络上个中免费的字体,添加各种不同的背景,对字体进行缩放旋转扭曲等操作,人工合成数据...
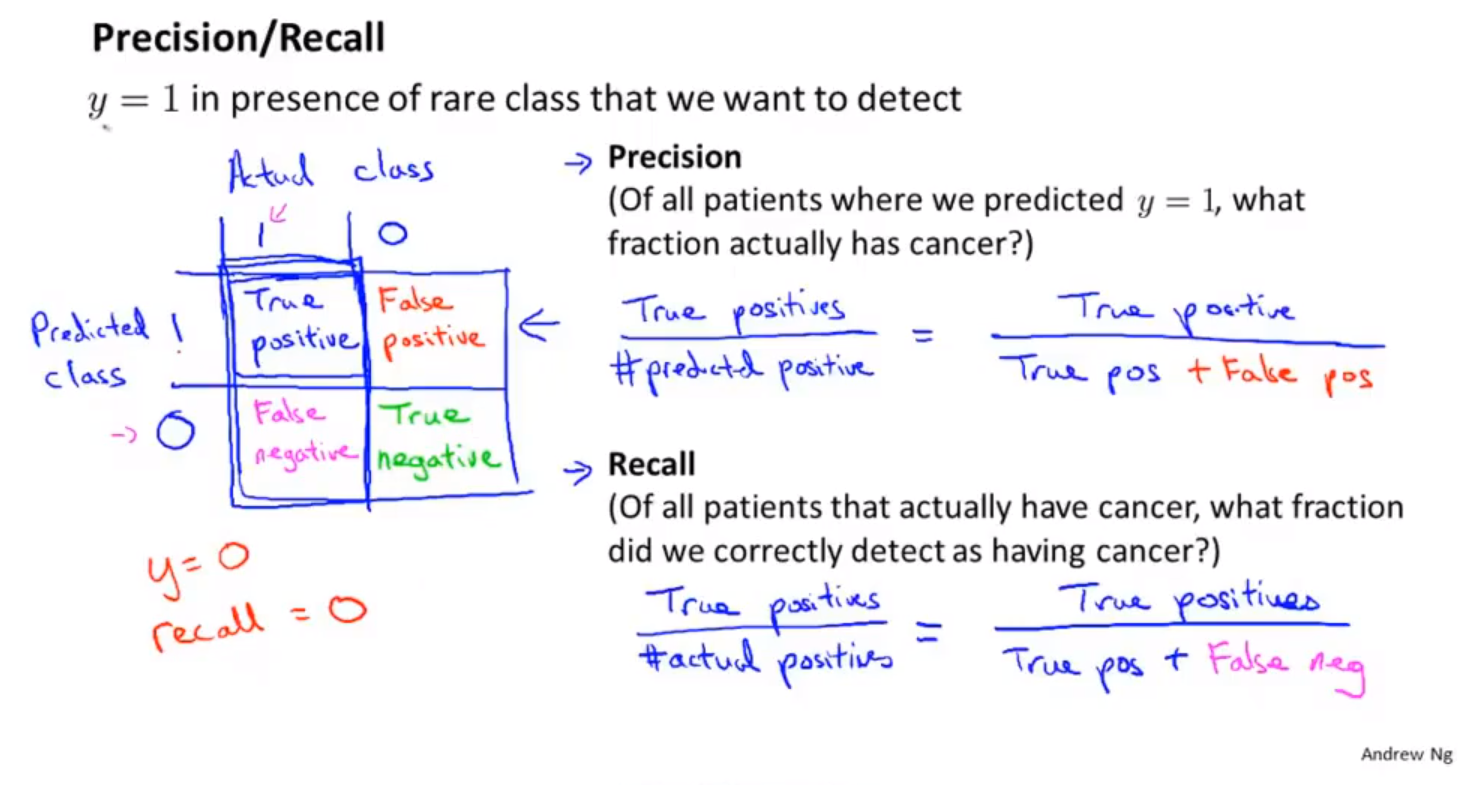
11机器学习系统设计
垃圾邮件分类系统误差分析机器学习实现的步骤 用最简单的算法快速实现机器学习过程。然后通过交叉验证数据集对模型进行测试。 画出学习曲线,通过检验误差,找出算法存在的高偏差、高方差问题。决定是否使用更多的数据和更多的特征。(不要过早的选择模型进行优化,应该首先对数据的特征进行分析。) 误差分析。通过分析错误数据,找到错误的原因,然后对机器学习算法进行改进。 数值估计。可以有效的改进机器学习算法。数值评估指标,来改进算法执行的效果。对数据进行特殊处理,例如只取邮件单词向量中单词前五个字母来训练数据。使用交叉验证错误率,来判断是否采取某项特殊处理。尝试各种不同的对算法的改进,然后使用交叉验证的方法,分析错误率的变化。 词干提取算法。 对算法的选择和改进 算法评估 误差分析 不对称分类的误差评估偏斜类 一个类别中的数据与另外一个类别中的数据量相差很大。 使用不同的方法,衡量偏斜类分类问题的准确率。 查准率和召回率 查准率:预测真实真值/预测真值。 召回率:预测真实真值/真实真值 在数理统计中使用第一类错误和第二类错误来描述查准率和召回率。只有增加样本的数量...

12支持向量机
支持向量机支持向量机的定义 逻辑回归的假设函数(sigmod)函数,将离散的分类,变成了连续的输出。建立与连续特征的函数关系。 支持向量机的假设函数,将sigmod非线性函数改为分段的线性函数。用来简化运算。 假设函数 支持向量机本身并没有给出假设函数。其本质上并不需要拟合出假设函数?不不不,支持向量机的假设函数$$h(\theta)=\theta^T * x$$ 代价函数 支持向量机的代价函数 $$J(\theta) =C \sum_1^m(y^{(i)}cost_1(\theta^Tx)+(1-y^{(i)})cost_0(\theta^Tx))+\frac{1}{2}\sum_1^n\theta_j^2\min (J(\theta))$$ 支持向量机的原理 大间距分类器。支持向量机会使得两个类别之间保持更大的安全距离。 参数C能够决定假设函数对数据的敏感程度。 大间距分类器的数学原理 $\theta^T*x$可以看做两个向量的內积 这个值越大,说明x在$\theta$方向的投影p越大,这个值越小,说明x在$\theta$方向的投影越小(为...

13聚类算法kmeans
无监督学习 数据集只给出了特征没有给出标签 找到隐含在数据中的结构 聚类算法的用途 市场分割 社交网络分析 组织计算簇 了解银河系的构成 kmeans聚簇 簇分配 移动聚类中心,到簇均值处(此时簇代价函数最小) kmeans算法的步骤 优化目标 kmeans的代价函数 $c^{(i)}$,第i个样本所属的簇 $u_k$,第k簇的簇均值 $u_{c^{(i)}}$,第i个样本所属的簇的簇均值 代价函数:所有样本到簇中心的距离均值。$$J = \frac{1}{m}\sum_i^m||x^{(i)}-\mu_{c^{(i)}}||^2\min J$$ 随机初始化 学习课程的算法演示,全部可以是自己构造的合适的数据,进行算法流程的模拟训练。具体的机器学习算法实践,专门开一个部分吧。 多次随机初始化,多次运行kmeans算法 对多次运行结果的聚类中心和代价函数进行保留,对比选取最小的结果。 聚类的数量 一般画出聚类样本的散点分布图,然后通过观察,手动决定聚类的数量。 肘部法则:尝试不同的K值,代价函数的变化,选...

15异常检测
异常检测异常检测动机 定义一个描述事件的特征向量 当事件发生的特征向量偏离正常事件的特征向量时,被认为是异常事件。 飞机引擎的各个参数,判断飞机引擎是否正常。 优点类似有监督学习,但是只给出了单侧数据集的标签。 高斯分布-正态分布异常检测算法 首先使用极大似然法,假定样本的每一个参数符合正太分布,给出正太分布的模型。 然后将样本代入概率模型,计算每一个特征的分布概率,然后连乘。 设定以个边界值,当概率小于某个边界值的时候,表示样本数据不正常。 在这里假定样本的各个特征之间相互独立,连乘表示其联合概率密度。 并不是一种极其学习算法,而是一种简单的数据预处理算法,或者说统计学方法,通过统计学的计算,确定新给的样本是否存在问题,完成异常检测。 开发和评估异常检测系统在开发机器学习系统的过程中,关键是做选择,而不是实现机器学习系统。应该学会选择特征、选择训练算法、选择预处理、选择错误检测算法的方法,通过组合现有的方法,达到一个比较好的效果。 使用高斯分布进行异常检测的过程中,只考虑了单个特征变量的分布,而没有考虑各个特征变量之间可能存在的关系。 使用训练集,计算高维高...

14主成分分析
降维-数据压缩 将两个具有强相关的维度,压缩到一个维度 方便计算 节约空间 学习算法运行更快 降维-数据可视化 选取具有代表性的两个维度来表示数据。 因为数据之间存在内在关联性。GDP的例子中,国家GDP低,人均GDP低的地方,医疗健康水平等其他指数也会很低。 主成分分析问题规划-目标 本质:找到一个低维度的面,然后将数据投影到上面,使得投影误差最小(在其他方向损失的数据信息最少。) 均值归一化 特征规范化 对数据进行缩放,避免因为数据本身的尺度不同造成对结果的影响不同。 主成分分析问题规划2 从线性空间的角度进行理解。当有n个特征的时候,可以用n个线性无关向量作为基,表示线性空间。如果这n个特征之间存在关系(线性相关性)那么可以用其他的特征来表示这个特征,那么就可以用n-1个向量作为基表示现行空间。 从向量空间的角度进行理解,主成分分析,即将n为空间内的点,投影到k维子空间当中,实现降维。 主成分分析即将n个特征之间的线性相关性进行判定。转换为互相独立的基,消除特征之间的线性相关性。如果n个特征之间存在线性相关,那么主成分分析的特征向量是n-1个,特征值也是n-1...
10算法改进
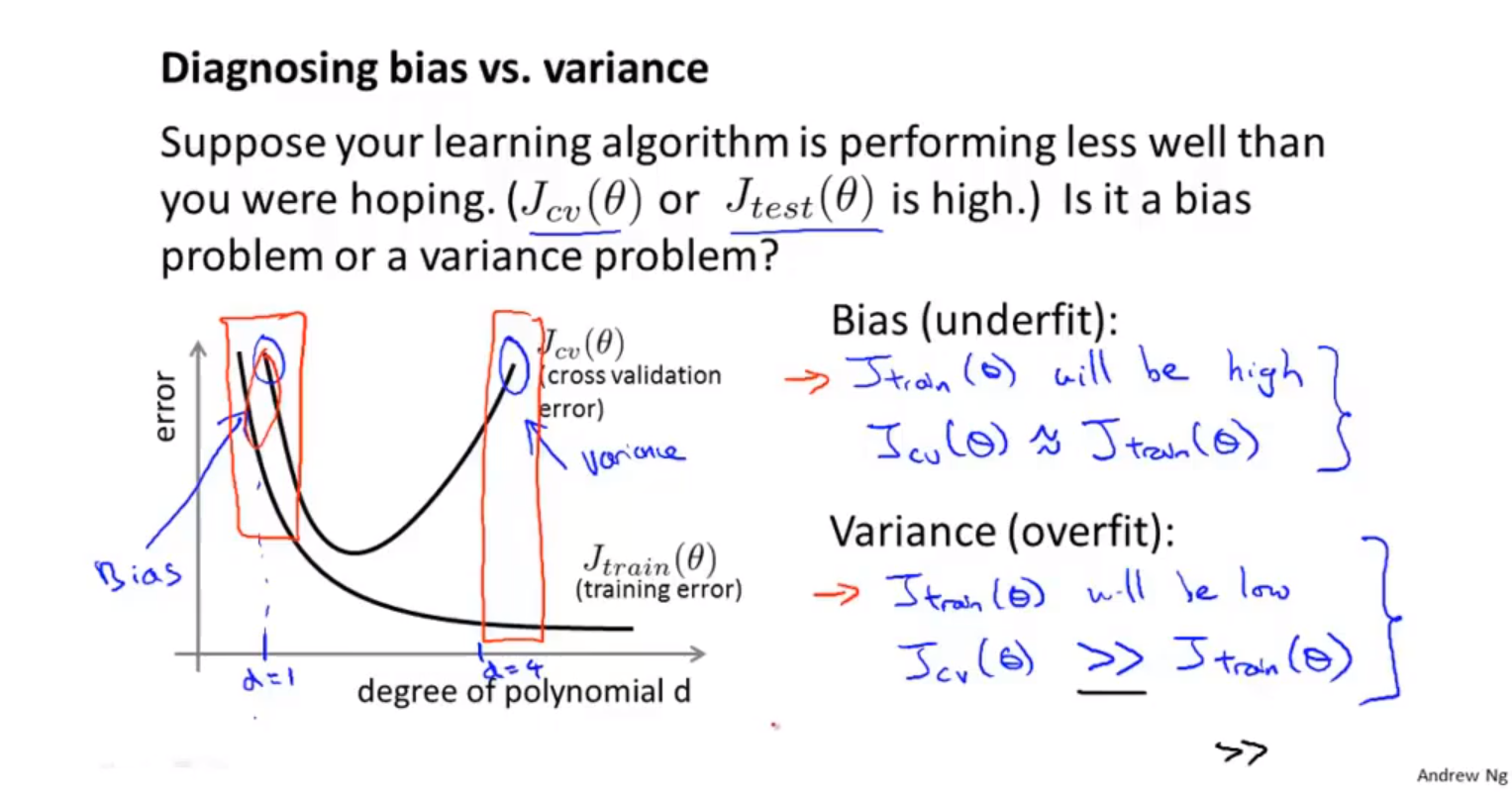
算法改进提高算法的性能 使用测试集后,模型训练的效果比较差。 解决办法: 使用更多的数据集进行训练。大部分情况下没有用。 尝试选用更少的特征。 添加更多的数据特征。 添加多项式数据特征(交叉数据特征) 修改正则化参数lambda的值。 评估假设 数据集分为训练集和测试集。7:3。 需要提前对数据进行随机化排列,然后进行训练集和测试集的划分。 然后计算测试集的均方误差。 对于分类问题可以,直接定义测试误差。 模型选择 数据集分为训练集、交叉验证集、测试集。6:2:2 假定多个不同的假设函数,使用交叉验证集,评估每一个假设函数训练出 的模型。选择效果最好的假设函数。 然后使用测试集对机器学习算法进行评估。 能够达到泛化误差的效果。 诊断偏差与方差 偏差较大,欠拟合。方差过大,过拟合。 当训练集与交叉验证集的误差都很高时,误差主要由偏差引起。 当训练集与交叉验证集的误差相差很大时,误差主要由方差引起,出现过拟合现象。 正则化与偏差和方差的关系 当正则化参数$\lambda$非常大时,会出现欠拟合的现象,此时代价函数的主要由参数引起,导致拟合过程中,训练参数无限制变小。 当...




