

08神经网络原理
非线性假设 当特征很多时,如果包含各种高阶项,特征空间会爆炸。 在非线性空间中,使用逻辑回归进行分类,会导致特征空间过多。 神经网络相关术语 input layer输入层 output layer输出层 bias unit 偏置单元 sigmod、logistic activation function激活函数 $\theta$模型参数=模型权重 模型展示 神经网络本身是机器学习的一个假设函数。 使用数学计算能够表示神经网络的计算过程。即计算给定输入后,计算神经网络的输出值。 使用向量化的计算方法,计算神经网络的前向传播过程。 实例 使用神经网络表示逻辑运算。 sigmod算子。+-10,+-20 计算向量化 普通计算向量化 多组数据矩阵化 使用向量,来表示计算过程。使用矩阵来表示多组数据的计算过程。 在线性回归和逻辑回归当中,多组输入向量,乘,固定的参数向量,等于,输出向量。 在神经网络中,一组输入向量,乘,多组参数向量,等于,输出向量。 下标用来表示矩阵和向量中的元素位置。上标表示迭代的代数。 编程任务:使用神经网络进行多元分类 寻找图片的数据集...

09神经网络实例
假设函数 神经网络本身,即是假设函数能够计算输入相对的输出。 代价函数 $L$表示神经网络的总层数。 $s_L$表示第L层单元的个数。 $K$表示输出层单元的个数 代价函数相当于第i组数据输入时,产生的误差。 $$J(\theta)=-\frac{1}{m}[\sum_i^my^{(i)}\log h_\theta(x^{(i)})+(1-y^{(i)})\log (1-h_\theta (x^{(i)}))]+\frac{\lambda}{2m}\sum_1^n\theta_j^2$$ $a^{(i)}$表示第i层的单元值。 $\Theta^{(i)}$第i层的权重 $z^{(i)}$第i层的加权值 $\delta^{(i)}$第i层的反向传播误差。 最小化代价函数:反向传播算法 在这里的上标,代表的不是输入的代数(即第几次迭代),而是神经网络的层数。下标表示的是神经网络某层的单元数。 原理:神经网络的值会随着假设函数正向传播。神经网络的误差会随着假设函数反向传播到第二层。利用每一层的单元值和神经网络的误差能够计算每一层的梯度下降向量,通过梯度下降向量,完成参...

工具说明
常见的编码工具 基于语法的 syntax high lighting:语法高亮工具。不同的语法部分,不同的代码颜色 code formatting:代码格式化工具。 基于语义的内容分析 intellisense:智能感知工具。包括自动补全、代码导航(选择)、符号识别。Edit your code with auto-completion, code navigation, syntax checking linting:代码审查工具。对代码中存在的warn、info、error进行分析,代码分析工具 snippets:代码片段工具。代码片段已检查如。 refactoring:代码重构工具。包括转到定义、转到声明、转到实现、转到引用(转到)。Restructure your Python code with variable extraction, method extraction and import sorting 代码运行过程中的问题 debuging:代码调试工具。 testing:单元测试工具

07拟合与正则化
过拟合偏差 bias 是系统性误差,由于模型本身引起的。 方差 var 是样本数据误差,由于样本数据的随机性引起的。 欠拟合与过拟合 jtrain训练集的代价函数。jcv交叉验证集的代价函数。jtrain能够通过训练过程,将样本随机性引起的误差降到最低。jcv没有经过训练过程,会最大化样本的随机性方差和模型本身的偏差。 高偏差:Jtrain和Jcv都很大,并且Jtrain≈Jcv。对应欠拟合。欠拟合的时候,由模型本身和样本的随机性引起的误差都很大。 高方差:Jtrain较小,Jcv远大于Jtrain。对应过拟合。过拟合后由样本随机性引起的误差会非常大。 低方差,高偏差。变量过多的时候出现的,训练得到的假设函数能够很好的拟合训练集,代价函数非常小。但是无法泛化到新的样本当中。 解决办法 减少特征的数量 对特征进行正则化。 正则化 代价函数加入正则化的数据项,用来缩小每一个参数。 现行回归的正则化代价函数$$J(\theta) = \frac{1}{2m}[\sum_1^m(h_\theta(x^{(i)})-y^{(i)})^2+\lambda\sum_1^...
3blue1brown
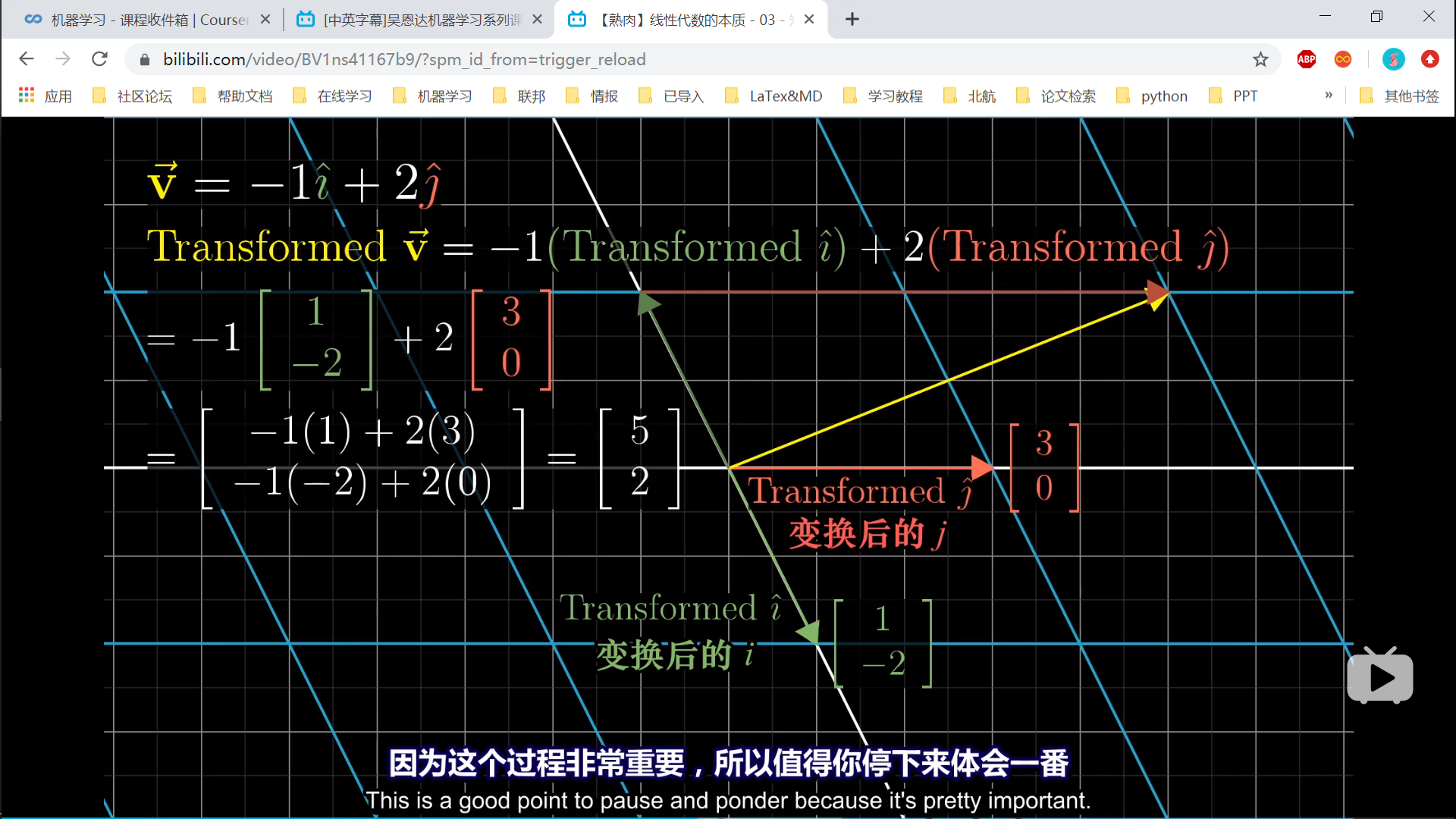
线性代数的本质 宇宙最强系列视频 向量的本质 图形=符号=坐标 线性组合、张成的空间与积 基向量i,j的可以表示向量空间。 任意两个向量的线性组合可以表示平面,称为向量的张成空间 不同的基向量,对向量空间的描述不同。 线性变换 线性变换:保持平行 原来的向量表示,乘以变换后的基向量表示 基向量变换。矩阵表示列向量的个数,列向量的每一个值,都表示向量的一个维度。矩阵的第一个维度,是所有列向量的第一个维度的排列。源向量的每一个维度,代表不同的基向量的scaling,缩放。 线性变换, 变换后的基向量=矩阵的列向量 原向量的每一个维度,都是对基向量的缩放。 目标向量的每一个维度,都是变换后的基向量在这一个维度的缩放的和。 [1,2,3,4]自身是1维数组,维度是4,能描述4个维度的数组。 矩阵乘法 批量的线性变换。 非方阵。行缺失,表示主成分保留,次要维度省略。 非方阵。行增加,表示补充了次要成分。

18constant
数字常量物理常量

04多元线性回归
多元线性回归问题 假设函数 $$h_\theta(x)=\theta_0+\theta_1x_1+\theta_2x+\theta_3x+\theta_4x\= [\theta_0,\theta_1,\theta_2,\theta_3,\theta_4]\times[1,x_1,x_2,x_3,x_4]^T\=\overrightarrow{\theta}^T\times\overrightarrow{x}$$ 代价函数 $$J(\overrightarrow{\theta})=\frac{1}{2m}\sum_{i=1}^m(h_\theta(\overrightarrow{x}^{(i)})-y^{(i)})^2$$ 梯度下降 $$\theta_j = \theta_j - \alpha\frac{\partial}{\partial\theta_j}J(\overrightarrow{\theta})$$ 特征放缩(归一化处理)当一个假设函数的多个特征处在相同的范围的时候,函数会更快的收敛。 均值归一化...

06逻辑回归分类
分类回归方式解决分类问题 存在奇异值会严重影响回归函数。 逻辑回归(假的回归方法)模型 训练集 $${x^{(1)},y^{(1)}},{x^{(2)},y^{(2)}},\dots,{x^{(m)},y^{(m)}}$$ 数据格式 $$x\in\begin{bmatrix} x_0\ x_1\ \vdots\ x_n\end{bmatrix}x_0=1,y\in{0,1}$$ m个训练集,n+1个训练参数 假设函数 $$h_\theta(x)=\frac{1}{1+e^{-\theta^Tx}}$$ 代价函数 $$cost(h_\theta(x),y)={\begin{aligned} -\log (h_\theta(x)) && y =1\ -\log (1-h_\theta(x))&& y=0\end{aligned}$$ 压缩版代价函数$$cost(h_\theta(x),y)=-y\log (h_\th...






