

04 pipelines快速开始
1 如何创建一个pipelines部署pipelines安装pipelines sdk安装kfp的python组件 1$ pip install kfp --upgrade 导入kfp相关的包 12import kfpimport kfp.components as comp 创建管道 创建合并数据的业务组件 函数的参数用 kfp.components.InputPath和 kfp.components.OutputPath注释进行修饰。这些注释让 Kubeflow Pipelines 知道提供压缩 tar 文件的路径并创建函数存储合并的 CSV 文件的路径。 用于kfp.components.create_component_from_func 返回可用于创建管道步骤的工厂函数。此示例还指定了运行此函数的基础容器映像、保存组件规范的路径以及运行时需要在容器中安装的 PyPI 包的列表。 123456789101112131415161718def merge_csv(file_path: comp.InputPath('Tarball'), ...
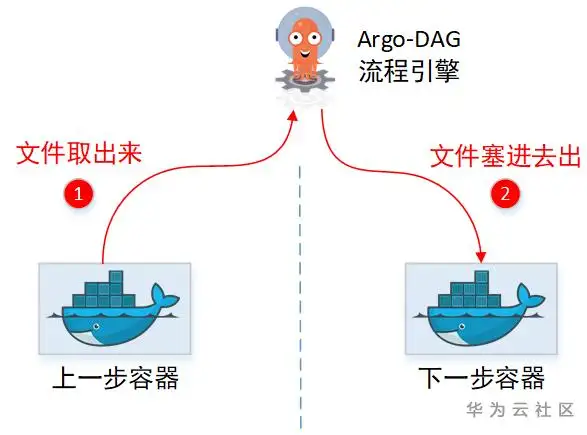
03 Pipelines原理
****## Kubeflow Pipelines 1 PipeLines介绍安装教程https://cloud.tencent.com/developer/article/1674948 使用教程https://juejin.cn/post/6844904195301064712 详细说明 https://blog.csdn.net/qq_45808700/article/details/132188234 1.1 Kubeflow Pipelines介绍kubeflow/kubeflow 是一个胶水项目,pipelines 是基于 kubeflow 实现的工作流系统,它的目标是借助 kubeflow 的底层支持,实现出一套工作流,支持数据准备,模型训练,模型部署,可以通过代码提交等等方式触发 Kubeflow 是一个基于云原生的Machine Learning Platform,它把诸多对机器学习的支持,比如模型训练,超参数训练,模型部署等等结合在了一起,部署了 kubeflow 用户就可以利用它进行不同的机器学习任务,旨于快速在kubernetes环境中构建一套开...


04 3.自定义请求和搭建集群
4 自定义Jmeter采样器 步骤 动作 1 创建一个Java类并继承AbstractJavaSamplerClient 2 实现setupTest方法,用于初始化 3 实现runTest方法,用于执行具体的请求 4 实现teardownTest方法,用于清理资源 5 编译并将生成的jar文件放入JMeter的lib/ext目录下 6 在JMeter中创建一个新的线程组 7 添加一个Java Request到线程组中,并设置相应的参数 8 运行测试,查看结果 步骤 1: 创建一个Java类并继承 AbstractJavaSamplerClient引入对应的依赖 1234567891011<dependency> <groupId>org.apache.jmeter</groupId> <artifactId>ApacheJMeter_core</artifactId> <version>4.0</version></depen...

34 JVM参数调优
引言Jvm(Java虚拟机)是Java语言的基石,对于Java应用的性能至关重要。而Jvm启动参数的优化是提高Java应用性能的一个重要手段。本文将介绍Jvm启动参数的优化和一些示例,帮助开发者更好地理解和优化Jvm的启动参数。java启动参数共分为三类;其一是标准参数(-),所有的JVM实现都必须实现这些参数的功能,而且向后兼容;其二是非标准参数(-X),默认jvm实现这些参数的功能,但是并不保证所有jvm实现都满足,且不保证向后兼容;其三是非Stable参数(-XX),此类参数各个jvm实现会有所不同,将来可能会随时取消,需要慎重使用; 优化方案Jvm性能优化Jvm性能优化是应用开发过程中关注的一个重要方面。通过优化Jvm启动参数,可以显著提升Java应用的性能。以下是一些常见的Jvm性能优化参数: 1234567-Xms: 指定Jvm的初始堆大小。-Xmx: 指定Jvm的最大堆大小。-Xmn: 指定Jvm的年轻代堆大小。-XX:MaxPermSize: 指定Jvm的永久代(或元空间)大小。-XX:SurvivorRatio: 指定Jvm的年轻代中Eden区和Survivor...

1.10 面向需求思想
面向需求编程无论是设计阶段还是编码节点,都要遵循一定的逻辑,先做什么后做什么。 在设计阶段,首先要明确具体的需求是什么。功能需求和非功能需求。然后才可以进行概要设计和细节设计。 在编码阶段,最上层接口根据设计文档定义。在实现过程中,相当于撰写下层接口的需求说明,期望下层接口返回什么内容,可以提供给下层接口哪些值。然后再去定义下层接口。这样往复循环就可以完成分层设计中的每一层。前提是需要提前设计好每一层、每一个模块的功能边界。 一种方法是遵循自顶向下的设计和自底向上的实现,但这种方法需要在写设计文档的时候就明确每个模块之间的交互。这是一种标准的设计和实现方法。 但现实是,一些内容只有在编写的时候才会知道每个类之间的交互是怎样的,有哪些方法需要抽象出新的类,类中每个方法的入口和返回值是什么。 所以可以遵循自顶向下的设计实现。即首先编写最上册的设计,然后进行实现,实现过程中对下层接口的需求就是对下层接口的需求。
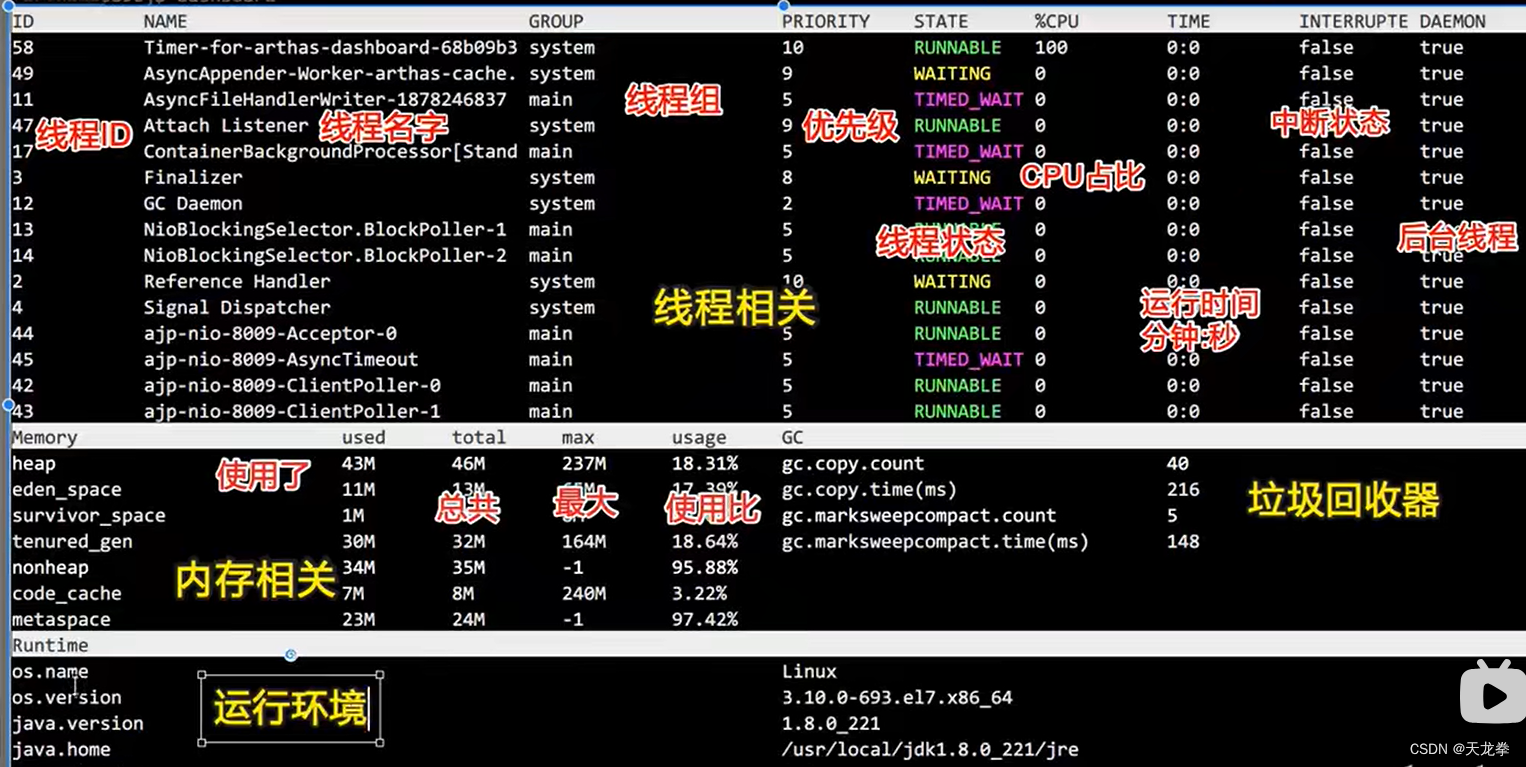
32 Arthas问题排查工具
1 简介概述Arthas 是Alibaba开源的Java诊断工具。可实时查看应用 load、内存、gc、线程的状态信息,并能在不修改应用代码的情况下,对业务问题进行诊断,包括查看方法调用的出入参、异常,监测方法执行耗时,类加载信息等,大大提升线上问题排查效率。 解决的问题1.这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?2.我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?3.遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?4.线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!5.是否有一个全局视角来查看系统的运行状况?6.有什么办法可以监控到JVM的实时运行状态? 参考文档https://blog.csdn.net/ls18802694089/article/details/134678902 https://arthas.gitee.io/doc/quick-start.html 2 使用1.下载启动demo java程序是一个简单的程序,每隔一秒生成一个随机数,再执行质因数分解,并打印出...
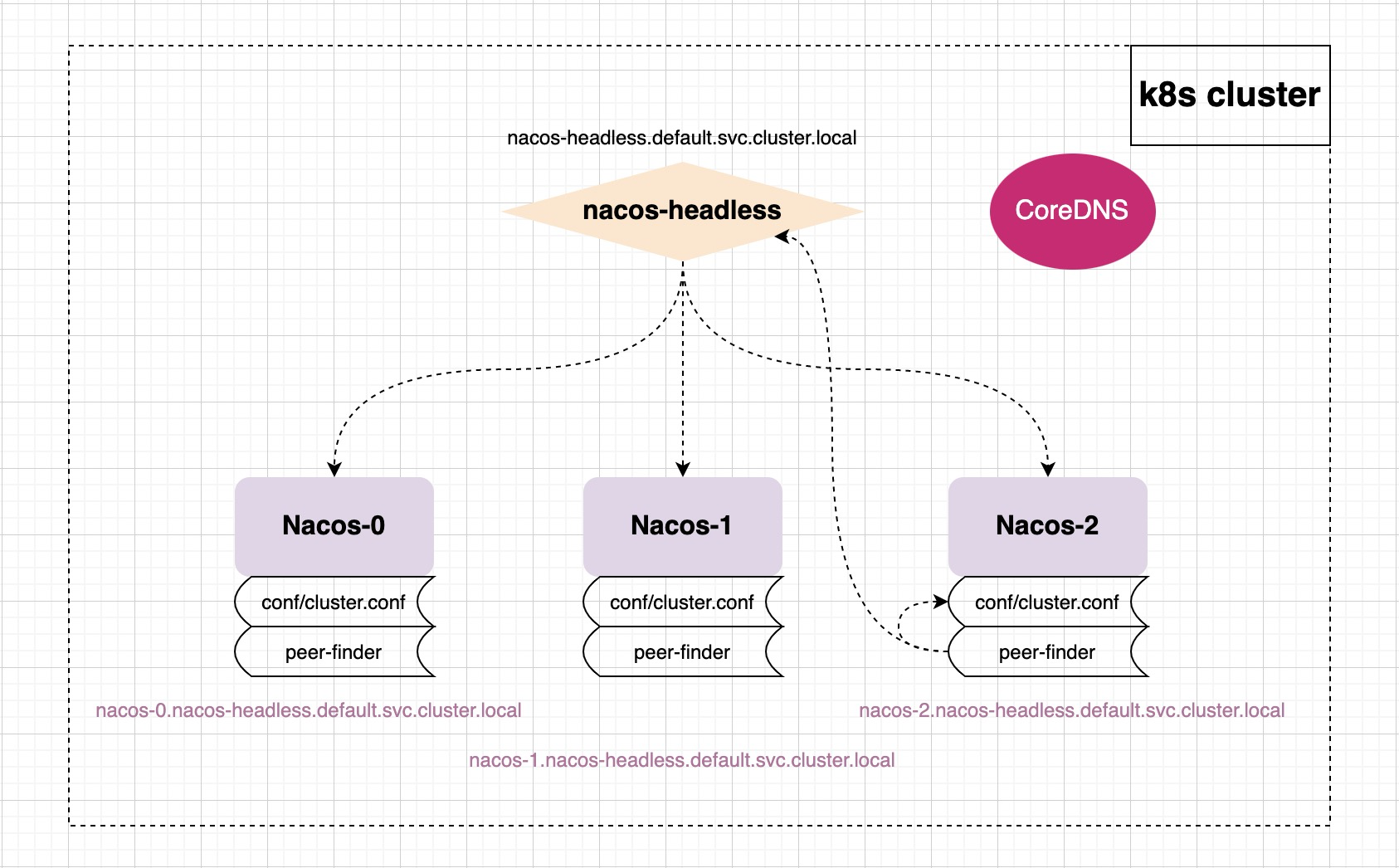
nacos-peer-finder
peer-finder 插件是用于不断地监听 nacos-headless 的服务列表变更,若列表有变更则写入 conf/cluster.conf nacos-0.nacos-headless.default.svc.cluster.local:8848 nacos-1.nacos-headless.default.svc.cluster.local:8848 nacos-2.nacos-headless.default.svc.cluster.local:8848
01 注册中心-Eureka
是什么cs架构,客户端连接到注册中心,维持心跳连接。30s一次,90s清除。 怎么用服务端 需要了解http长连接的实现方案。需要了解一下raft协议相关的内容。看完视频以后,把这里的文档补充完整。已经收藏了一些相关的优秀博客。





