
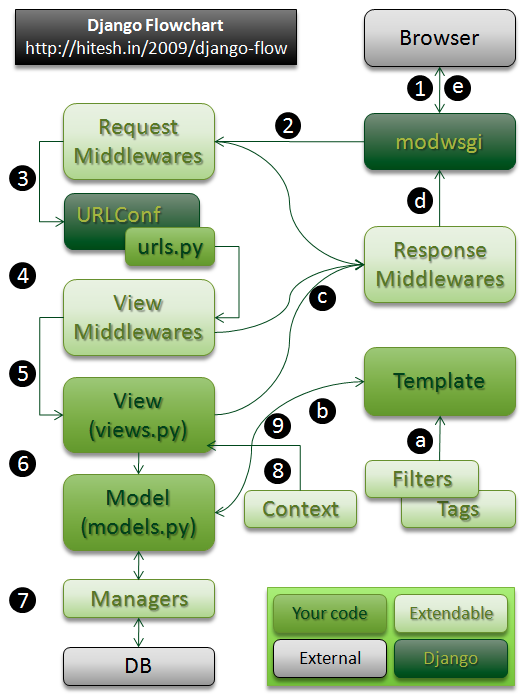
Django——基本理解
http请求处理的MVC结构 HTTP处理的中间件结构 记住几个重要的预处理函数 process_request(self, request) request预处理函数 在Django接收到request之后,但仍未解析URL以确定应当运行的view之前。调用 返回 None(Django将继续处理这个request,执行后续的中间件,然后调用相应的view,“我对继续处理这个request没意见”) 或者返回 HttpResponse 对象(Django将不再执行任何其它的中间件(无视其种类)以及相应的view。 Django将立即返回该HttpResponse,“我不想其他代码处理这个request,我要提早返回” ). process_view(self, request, callback, callback_args, callback_kwargs) view预处理函数 在Django执行完request预处理函数并确定待执行的view之后,但在view函数实际执行之前。 process_response(self, request, response) Res...

django进阶——Settings
MEIDIA_ROOT 保存用户上传的目录和系统绝对文件系统路径。 - 处理从MEDIA_ROOT提供的媒体的URL,用于管理存储的文件。 如果设置为非空值,则它必须以斜杠结尾。 您将需要将这些文件配置为在开发和生产环境中提供服务。 - 如果您想在模板中使用{{MEDIA_URL}},请在“模板”的“context_processors”选项中添加“django.template.context_processors.media” MEDIA_URL 引用或者说访问MEIDIA_ROOT中的文件时使用的URL,即客户通过浏览器访问的路径。 STATIC_ROOT 用来保存静态文件(搭建网站的css库,scrip脚本,图片),默认值为none。收集静态文件进行部署的目录的绝对路径 STATIC_URL 引用STATIC_ROOT中静态文件时使用的URL - 如果不是 None,这将被用作资产定义(Media类)和staticfiles应用程序的基本路径。 - 如果设置为非空值,则...

Django——数据库操作复习
这个是当前最终要的一部分知识,因为接下来的工作包括太多的数据库操作了,必须得详细了解一下。 -————————————————————————————————————– 关于模型的说明 字段选项 定义字段过程中对字段的性质进行控制 null blank choices db_column db_index db_tablespace default auto_to_now error_messages help_text primary_key(主键) unique(唯一性) unique_for_date unique_for_month unique_for_year verbose_name 验证器 注册和获取查询 字段类型 定义字段的类型 AutoField自增字段 BigIntegerField 二进制字段 BooleanField For CommaSeparatedIntegerField rendering DateField DecimalField DurationField EmailField...

django进阶——models
文件上传字段FileField(upload_to=Node,max_length=100, **options)[source] FileField.upload_to 此属性提供了一种设置上传目录和文件名的方式,可以通过两种方式进行设置。在这两种情况下,该值都将传递给Storage.save()方法。 如果您指定了一个字符串值,它可能包含strftime()格式,将由文件上传的日期/时间替换(以便上传的文件不填满给定的目录)。例如: class MyModel(models.Model): # 文件将会上传到 MEDIA_ROOT/uploads upload =models.FileField(upload_to=’uploads/‘) # or… # 文件将会保存到MEDIA_ROOT/uploads/2015/01/30 upload =models.FileField(upload_to=’uploads/%Y/%m...
django进阶——登录验证实现
User对象字段 username password email first_name last_name 创建User User.objects.create_user() user.save() manage.py createsuperuser manage.py changepassword username 验证User的用户名密码 authenticate(username, password) from django.contrib.auth import authenticate user =authenticate(username**=‘john’, password=‘secret’)if user isnot None: # the password verified for the user if user.**is_active:print(“User is valid, active and authenticated”) else: print(“Thepassword is valid, ...

Scrapy框架学习——ItemLoaders
ItemLoader是为了将获取文本进行分解,装载到相应的ItemLoader当中。 具体方法: def parse(self, response): l = ItemLoader(item**=Product(),response=response) l.add_xpath(‘name’, ‘//div[@class=”product_name”]’)l.add_xpath(‘name’, ‘//div[@class=”product_title”]’)l.add_xpath(‘price’, ‘//p[@id=”price”]’) l.add_css(‘stock’, ‘p#stock]’)l.add_value(‘last_updated’, ‘today’) # you can also use literal valuesreturn l.**load_item() ItemLoader在每个字段中包含了一个输入处理器和一个输出处理器。 输入处理器收到...

Scrapy框架学习——Items使用
>准确的说,scrapy主要就有两部分可以编辑,一个使用来处理数据的scrapy.Items,另一个用来仓库 Item的操作包括创建、获取字段的值、设置字段的值、后去所欲的键、获取product列表、获取product字段、社赋值和浅复制、集成扩展item。 Item对象的操作 fields内置字段,是item生命中使用到的field对象的名字,是一个字典。

Scrapy框架学习——命令行工具
全局命令<不需要要项目,在命令行中直接运行>: scrapy startproject myproject - 创建一个名为myproject的scrapy项目 scrapy genspider [-t template] <name> <domain> - 创建一个新的spider(-l 列出spider的模板,-d 查看模板的内容 -t 使用这个模板) scrapy -h - 查看所有可用的命令 scrapy crawl <spider> - 使用spider进行爬虫 scrapy check [l] <spider> - 运行contract检查 scrapy list - 列出所欲可能的spider scrapy edit <spider> - 使用设定的编辑器编辑spider scrapy fetch <url> - 使用scrapy下载器Downloader下载给定的URL,并将获取到的内容标准输出 scrapy view <url> - 用来查看spider获取到的页面,...
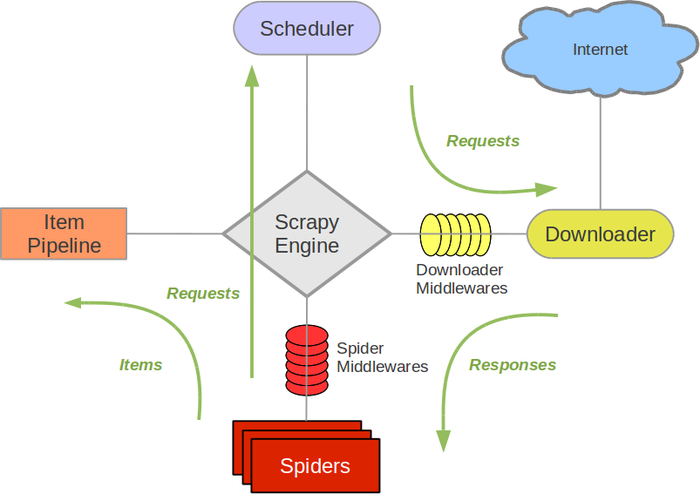
Scrapy框架学习——琐碎知识整理
scrapy引擎 调度器 Spiders 下载器 Item Pipeline itemloader用来装载,item用来容纳,itempipeline用来过滤。也负责了指明了存好数据的item的数据流动的方向。itemloader是活动在原始数据和item之间的桥梁。itempipeline是活动在item和具体存储数据的位置之间的桥梁。比如用来操纵数据库、用来写入文件,用来提供下一次爬虫的相关信息。 下载器中间件 由调度器具体指挥,能够根据引擎发送的request对象,封装真正的request请求,并且设置请求的响应参数。不同的下载器中间件,能够完成不同的任务。 Spider中间件 引擎和Spider之间的钩子。用来处理Spider发送给引擎的request和Item和引擎发送给Spider的response。有点像网络的分层,没一层都向发送数据中添加一点内容,每一层都从接受数据中获得一点内容。有很多中间件,可以在这里过滤掉一些错误。另外,如果错误能够越提前的发现,则越有利于提高效率。 扩展Extension和信号signal 框架提供了一个很好的扩展机制。在配置文件中声明,...

Xpath学习 CSS选择器学习
XPath使用路径表达式来选取XML文档中的节点或者节点集合。节点是通过path或者步来选取的。 1. 通过已经有的表达式选取节点、元素、属性和内容 nodename 选取此节点的所有子节点 / 从根节点开始选取 // 从匹配选择的当前节点选择文档中的节点 . 选取当前节点 .. 选取当前节点的父节点 @ 选取属性 2. 带有位于的路径表达式,使用[ ]来表示当前节点被选取的一些条件 /bookstor/book[price>35]/title 3. 通配符来选取未知的元素(一般也用python的re表达式) * 匹配任何元素的节点 @* 匹配带有任何属性节点(没有属性的节点不行) node() 匹配任何类型的接待你。 对于CSS来说,选择器与HTML和CSS相关。 .class intro 查找类别下的元素 #id #firstname id=*的所有用户 element p 选择所有的元素 element,element 并列选择 element element 父子选择 element>ele...




